1685 edycji w godzinę
Zainteresowało mnie narzędzie Depictor. Po tym jak
potestowałem i okazało się że można to szybko robić sprawdziłem i
tak szybko edycji jeszcze nie nabijałem.
Edytowanie jest proste – porównuje się czy na zdjęciu (pobranym
z kategorii z Commons) jest osoba, której zdjęcie jest już na
Wikidanych (zdjęcie przypięte do Wikidanych jest po drugiej
stronie).
Część wywołań jest trywialnie prosta:
Czasem trzeba spojrzeć drugi raz
Czasem naprawdę nie wiadomo (wtedy jest opcja „skip”). Czasem to
nie jest ta osoba (głównie zdarzają się zdjęcia podpisów danej
osoby) – wtedy oznacza się jako „nie”.
Ponieważ głównym ograniczeniem w szybkim oznaczaniu jest
przeładowywanie zdjęć (zajmuje to jakieś 3-4 sekundy) po kilku
dniach doświadczenia postanowiłem po prostu odpalić 25 tabów w
przeglądarce z tym samym zapytaniem i używając kombinacji CTRL+TAB
skakać przez wszystkie taby. A że klawisz „1” służący do dodawania
automatycznie wpisu jest blisko na lewej ręce więc układ wygląda
tak że cały czas lewa ręka skacze po CTRL+TAB i 1, a prawa ręka
jest na myszce i odświeża strony w razie problemów z połączeniem
(bardzo rzadko).
Błędy się zdarzają, bo czasem za szybko kliknę „1”. Zwykle wtedy
skaczę zaraz do wkładu na Commons i poprawiam. Zdarzyło mi się
oznaczyć jako „nazwisko wokalisty” wszystkich członków zespołu
wokalisty – to już był dla mnie duży błąd bo mi na to zwrócili
uwagę.
Ale ogólnie 99,9% zdjęć zawiera daną osobę. Świadomie zaczynałem
od osób urodzonych w obecnym wieku – więc np. sportowcy którzy
wystąpili na ostatnich igrzyskach zimowych urodzili się bardzo
często w 2001-2002 roku. Więc oznaczyłem całe stada curlerów i
snowboardzistów. Ciekawe jest to że jak na razie polityków było
mało. Dojechałem do osób urodzonych w 1997 roku i pojawiali się
pojedynczo. Poza curlerami było też dużo piłkarzy obu płci,
koreańskich piosenkarek, amerykańskich kierowców i koszykarzy.
Czasem jest tak że jakiś fotograf wybrał się na konkretne zawody –
miałem przypadek gdy były dziesiątki fotek z kobiecej piłki ręcznej
rozgrywanej na piasku.
Ogólnie bardzo polecam.
A po co to? Bo obecnie bardzo ciężko jest powiedzieć „na commons
jest X zdjęć osoby Y”. Nie wiadomo ile jest fotek Jerzego Kuleja
(bo mogą być w takich podkategoriach jak „Jerzy Kulej w roku XXXX”
popularnych wśród aktorek i piosenkarek). A tak – po oznaczeniu że
na danej fotce jest dana osoba, można zapytać o to za pomocą
SPARQLa znanego z zapytań wikidanowych (znanego ludziom – nie
mi).
Zdarzają się tez fotki źle pokategoryzowane, ale to jest
rzadkość. Choć czasem są śmieszne pomyłki:
Osiemnasta rocznica powstania Polskiej Wikipedii. To całkiem
znacząca data w życiu projektu - polska Wikipedia osiągnęła
dojrzałość, przynajmniej w potocznym tego słowa
rozumieniu.
Ten dzień skłania także mnie do refleksji, wspomnień o początkach,
oceny stanu obecnego i prognozy na przyszłość.
Według mnie nie jest to czas i miejsce żeby wspominać, kto kogo
podsadzał do przeskoczenia muru Britanniki, czy ile centymetrów
grubości miał styropian, na którym spaliśmy znużeni godzinami
edytowania i dodawania nowych haseł.
Jak powstała Wikipedia ? Czy kluczową rolę odegrał Jimmy Wales czy
też Larry Sanger ? Chciałbym zwrócić uwagę na kogoś innego, na
cichego bohatera, bez którego Wikipedia w obecnym kształcie pewnie
nie powstałaby.
Ward Cunnigham - programista i wynalazca oprogramowania
wiki, które stworzył w 1995 r. Ma on hasło w polskiej
Wikipedii - zaledwie parę linijek.
To wizjoner i geniusz, który zmienił paradygmat Internetu. Ze stron
zamkniętych, będących strzeżoną własnością i podanych do konsumpcji
internautom, stworzył rodzaj stron internetowych, które (prawie)
każdy może zmieniać lub tworzyć. To był ważny krok w ewolucji
Internetu w kierunku mediów społecznościowych.
Nawiasem mówiąc, niektórzy uważają Wikipedię, za specyficzny rodzaj
portalu społecznościowego.
Polska Wikipedia to przede wszystkim Wikipedyści.
Moim zdaniem to Wikipedystom należy się podziw i słowa uznania.
W Wikipedii Wikipedyści wypełniają różne zadania. To nie tylko
pisanie haseł, ale działania techniczno-edytorskie, administracyjne
czy programistyczne.
Oczywiście najbardziej widocznym i miarodajnym wyznacznikiem są
hasła dobrej jakości.
Jest grupa Wikipedystów tworzących hasła bardzo dużym nakładem
pracy, hasła które przez ogół Wikipedystów są oceniane jako dobre
lub na medal.
Autorów (lub głównych autorów) takich haseł można by śmiało nazwać
czempionami Wikipedii i ich na eventach powinno się wprowadzać na
scenę z fanfarami i po czerwonych dywanach.
Wystarczy powiedzieć, że opracowanie jednego hasła wartego
wyróżnienia może zająć nawet kilka ładnych miesięcy codziennej
pracy.
Ale nie tylko najlepsze i wyróżnione hasła mają swoją wartość.
Przez te 18 lat bardzo fajnie było zauważać, że coraz więcej haseł
w polskiej Wikipedii to najlepsze, najlepiej opisane i najbardziej
obiektywne informacje na dany temat w całym polskim
Internecie.
Nie umniejsza to roli innych Wikipedystów, bo moim zdaniem, ważne
jest, żeby nie wytwarzać w Wikipedii hierarchii i zachowywać ogólne
zasady egalitaryzmu i fair play - także w stosunku do Wikipedystów
z bardzo krótkim stażem.
Mówiąc o społeczności Wikipedystów chciałbym z tego miejsca oddać
sprawiedliwość wszystkim, którzy przyczynili się do rozwoju
polskiej Wikipedii.
Muszę się przyznać, że za każdym razem odczuwam zażenowanie, kiedy
ludzie dziękują mi za Wikipedię lub wyrażają podziw, że jestem jej
współzałożycielem.
To wszystkim Wikipedystom należą się te podziękowania i
uznanie.
Co do przyszłości polskiej Wikipedii, to mam nadzieję, że przez
następnych parę ładnych lat, roboty i sztuczna inteligencja nie
zastąpią ludzi-Wikipedystów.
Niech to nadal będzie wielki fun, frajda i satysfakcja pisać
wspólnie największą i najlepszą encyklopedię na świecie.
Hasła polskiej Wikipedii
przetłumaczone z innych języków
Hasła polskiej Wikipedii to nie tylko mozolna praca licznych rzesz
polskojęzycznych edytorów. Czasem Wikipedyści znający języki obce
zabierają się za tłumaczenie haseł z innych wersji językowych
Wikipedii.
Poniższy przegląd nieco zaskakuje. To, że angielski jest na 1.
miejscu nikogo nie zdziwi, ale na przykład 4. miejsce czeskiego czy
8. miejsce ukraińskiego jest całkiem niespodziewane.
Jestem pod wrażeniem haseł przetłumaczonych z takich "egzotycznych"
języków jak: wietnamski, łotewski czy luksemburski.
Czytam książkę
„Zarządzanie organizacjami pozarządowymi” wydaną przez UJ.
Myślę, że jej treść może Was zainteresować w kontekście zmian w
Stowarzyszeniu Wikimedia Polska, o których będziecie rozmawiali na
jutrzejszym walnym zebraniu. Niestety, z powodu śmierci krewnego
nie mogę jechać do Wrocławia. Stąd ten post.
Od kilku lat spędzam dużo czasu nad
strategią całego ruchu Wikimedia. Dzięki temu mam szeroką
perspektywę na polskie podwórko. Przy okazji, metodą małych
kroczków, zacząłem przeznaczać czas na sprawy związane z
zarządzaniem naszym Stowarzyszeniem. Oczywiście nie jako członek
zarządu. Moja rola jest wygodniejsza: działam jako wolontariusz z
6-letnim doświadczeniem w komisji Wikigrantów, pomocny prawnik,
delegat do KOED-u… Postanowiłem, że jako zwykły wolontariusz
podzielę się wiedzą z innymi zwykłymi wolontariuszami.
Funkcje Stowarzyszenia
Według tego, co przeczytałem,
wyróżnia się klasycznie 3 funkcje organizacji pozarządowych:
samopomocową – polega na rozwiązywaniu
problemów członków grupy, na umożliwianiu spędzania czasu osobom o
podobnych zainteresowaniach i dzielenia się pasjami czy opiniami.
Wydaje mi się, że jest to pierwotna i główna funkcja
Stowarzyszenia. Temu służą zloty, Wikigranty, a częściowo także
fakt, że mamy rzecznika prasowego,
usługową – polega na świadczeniu usług
publicznych. Wikimedia zawsze działały w dziedzinie edukacji, na
rzecz powszechnego dostępu do wiedzy. Ale od kiedy samo
Stowarzyszenie zaczęło pełnić funkcję usługową? Myślę, że od wtedy,
kiedy zaczęło współpracować z innymi instytucjami. Chodzi
szczególnie o GLAM (galerie, biblioteki, archiwa, muzea) oraz PSiA
(projekty szkolne i akademickie),
rzecznikowską – polega na wywieraniu wpływu na
debatę publiczną w celu zmiany prawa lub postaw społecznych. Ta
funkcja może zawsze była, a obecnie na pewno jest, najsłabsza.
Chyba dlatego, że w praktyce jest oddalona od funkcji
samopomocowej. Poza tym członkami Stowarzyszenia są edytorzy, a tak
się składa, że pokolenia edytorów się zmieniają i społeczność traci
charakter grupy ideologicznie zapalonych prawnoautorskich
aktywistów. Rzadko rozmawiamy o Stallmanie, prawda?
Poza tym wyróżnia się funkcje
„uświadomione” (intencjonalne, deklarowane) oraz „nieuświadomione”
(postrzegane z zewnątrz, niekoniecznie znane członkom
organizacji).
Czy Stowarzyszenie potrzebuje
pracowników?
„Po co Stowarzyszeniu pracownicy?
Kiedyś ich nie było i było w porządku” – takie pytania padają raz
na jakiś czas. Wcale się temu nie dziwię. Takie sprawy należy jasno
artykułować. Moja odpowiedź brzmi: tak, potrzebuje i to różnych.
Poniżej wymieniam powody sensu zatrudniania.
Stowarzyszenie nie jest wyłącznie
organizacją samopomocową
To, że Stowarzyszenie pełni funkcję
samopomocową, jest oczywista dla edytorów. Ale jeżeli weźmiemy pod
uwagę, że istnieje pisanie artykułów na zaliczenie, że Wikipedia ma
większą oglądalność niż strony internetowe muzeów, że poważne
organizacje i instytucje zgłaszają same chęć współpracy – staje się
jasne, że Stowarzyszenie nie działa wyłącznie dla edytorów. Służy
teżczytelnikom i
interesowi społecznemu. Chodzi m.in. o ochronę
dziedzictwa kulturowego (GLAM), polską oświatę i naukę (PSiA) czy
rzecznictwo w sprawach prawnych (np. ACTA2). W grę wchodzą
„nieuświadomione” funkcje Wikimedia Polska.
Stowarzyszenie nie jest małą
organizacją
Wyróżnia się organizacje małe
(lokalne, niektóre hobbystyczne), średnie (ogólnokrajowe) i duże
(międzynarodowe). Wikimedia Polska nie jest małe i hobbystyczne,
jak się może wydawać. Jest średnie i jest OPP. I ma silną
markę.
Stowarzyszenie ma własne
potrzeby
Minimum to obsługa biura,
księgowość, czasem prawnik. Zadania wynikające z większych ambicji
to np. organizowanie spotkań (zarządu i pracownic, konferencji
itd.), pisanie sprawozdań i wniosków grantowych, rozliczanie
(choćby dla własnej wiadomości) wykonanych zadań, kierowanie
całością działań operacyjnych (takich na co dzień).
Stowarzyszenie robi dużo, a może
jeszcze więcej
Stowarzyszenie jest stabilne
finansowo, ma dużo pieniędzy i może mieć więcej. Prawie żaden
afiliant Wikimedia nie ma takiego mechanizmu jak OPP (co roku
wpływają sumy dające operacyjną niezależność od Wikimedia
Foundation). Do tego dochodzą fundusze od WMF (pobierane z wyboru,
a nie z braku wyjścia, na cele ambitne, a nie na podstawowe
przeżycie typu długopisy i papier ksero). Są też dostępne środki
publiczne i granty innych organizacji. Stowarzyszenie ma dobrą
historię finansową, jego projekty prezentują się dumnie, jest
potencjał pozyskiwania funduszy.
Zarząd wydaje pieniądze ostrożnie
na liczne projekty. Natalia mówiła mi, że była pozytywnie
zaskoczona tą liczbą, kiedy pisała sprawozdanie roczne na potrzeby
WMF. Miałem to samo, kiedy pisałem nową stronę „Projekty” na wiki
Stowarzyszenia. A przecież Wikimedia Polska może robić więcej. W
ramach funkcji samopomocowej może płacić za pisanie i utrzymywanie
szczególnie skomplikowanych, dużych gadżetów i skryptów. W ramach
funkcji usługowej może zacząć regularnie współpracować z
uczelniami. W ramach funkcji rzeczniczej może więcej mówić o prawie
autorskim – akurat będziemy wchodzili w etap wdrażania tzw.
ACTA2…
Część zadań wymaga połączenia
umiejętności, odpowiedzialności i tempa
Przychodzą pisma urzędowe z
obowiązkiem odpowiedzi w terminie 7 czy 14 dni. W razie poważnych
uchybień każdy członek zarządu odpowiada swoim majątkiem.
Przychodzą też telefony w godzinach roboczych, itp. Wolontariusz
mógłby odpowiedzieć „dziś nie mam czasu”, ale podmiot prawny nie ma
komfortu powoływać się na to, że ktoś akurat nie miał czasu.
Wolontariusze oczekują, że coś się
zrobi w odpowiednim tempie
Samo nic się nie załatwi. Ktoś musi
bookować bilety, przyjmować faktury, przygotować nagrody konkursu
fotograficznego czy edycyjnego, organizować na konferencji temu
bezmięsne, a tamtemu halalne.
Zużywanie najlepszego z zasobów
jest złe
Najlepszym, najcenniejszym zasobem
Wikimedia są wolontariusze. Tymczasem wykonywanie licznych zadań,
które nie mają nic wspólnego z motywacją edytowania Wikipedii, jest
męczące. Wręcz wypalające. Dlaczego we władzach nie ma Powerka czy
Polimerka? Dlaczego Masti chętniej mówi o Wikidanych niż o nowych
zestawieniach wydatków? Ilu dobrych wikipedystów chcemy jeszcze
przemielić przez odpowiedzialność za dużą organizację?
Stowarzyszenie może bliżej
zaangażować wartościowych ludzi
Nie wszyscy mogą zostać tak
ofiarnymi wolontariuszami, jak by chcieli, na przykład ze względów
osobisto-rodzinno-finansowych. Jednocześnie są pełni energii o
wiele większej niż typowi edytorzy i mają umiejętności, których
Stowarzyszenie bardzo potrzebuje. Praca dla organizacji
pozarządowej daje wielką i specyficzną satysfakcję. Czasami jest
lepiej umówić się na kawałek etatu za pieniądze i mieć wykonaną
pracę, niż liczyć na okazjonalną pomoc wolontariacką i ryzykować
opóźnienie.
***
Stowarzyszenie jest organizacją o
dużych możliwościach. Niestety, obecny model zarządzania nie
przystaje do potencjału. Dlatego popieram liczne drobne zmiany w
statucie, np. wprowadzenie możliwości kooptacji do zarządu
maksymalnie dwóch osób niebędących członkami, a mających
umiejętności, których brakuje wśród członków. Będzie o dwóch
niewypalonych edytorów więcej. Na Walnym zapewne usłyszycie jeszcze
więcej przemyśleń członków zarządu. Spodziewam się, że będą w
podobnym tonie do mojego.
Z racji tego, że wikiżycie raczej chłoszcze niż głaszcze
ostatnio – zdałem sobie sprawę że sprawia mi przyjemność
poprawianie błędów Wikipedystów. Więc sprawdziłem ile da się
poprawić w ciągu jednej godziny błędów z
tej listy
Wynik: 277 edycji w godzinę zegarową.
Poprawki nie są zbyt ambitne, ale np. jeżeli chodziłem przez dwa
miesiące by ktoś posprzątał legendy zawodników zimowych, a w końcu
mogłem sam
coś tam zrobić, to było to odświeżające.
Czasem też zdarzają się
zadziwiające sytuacje. Prawdopodobnie są to pozostałości
czegoś, co było dawniej. Ale co ma sądzić niedoswiadczony
użytkownik widzący taki kod w haśle?
Czasem bywają też
takie problemy, ze człowiek się zastanawia jaka jest historia
tego hasła, że coś takiego zostało.
A czasem po prostu zamiast skasować zakończenie, trzeba
dodać początek znacznika.
Bywają też sytuacje, które nigdy nie działały i dopiero moja
edycja powodowała „efekt”.
Jest kilka rzeczy, które sprawiają, że Wikipedia jest takim
wyjątkowym i wartościowym projektem internetowym.
Czy bez rygorystycznego wymagania podawania (wiarygodnych) źródeł
Wikipedia byłaby coś warta ? Zdaniem raczej nie.
Spójrzmy na wikipediowe wyróżnione hasła - to przecież porządnie
opracowane, merytoryczne i opatrzone przypisami
mini-monografie.
Chociaż na początku Wikipedii, każdy pisał na podstawie swoich
wiadomości i materiałów, to po pewnym czasie wprowadzono zasadę
weryfikowalności.
I bardzo dobrze. Podajesz fakty i informacje, musisz podać skąd je
wziąłeś, z
zastrzeżeniem że źródła informacji są wiarygodne.
Dla mnie "wychowanego" na EBM (↤ sprawdź w Wikipedii) informacja związana z
medycyną, czy szerzej zdrowiem musi mieć solidną dawkę "porządnych"
źródeł. Inaczej na pierwszy rzut oka, dla mnie, coś jest nie
tak.
Wstawiając przypisy medyczne do haseł Wikipedii, zacząłem się
zastanawiać, że dobrze byłoby mieć zbiór dobrych, wiarygodnych i
sprawdzonych przypisów z których można by czerpać w łatwy
sposób.
Wkrótce potem dowiedziałem się o Wikicite.
W zamyśle i projekcie, yo wolna (libre) i otwarta zbiornica danych
z cytowaniami (plus metadane bibliograficzne), która może być
wykorzystywana w projektach Wikimedia, a także na zewnątrz.
Ten umocowany w Wikidata (Wikidanych) projekt jest w fazie
tworzenia. Niewielka grupa naukowców, deweloperów i entuzjastów
ostro ruszyła z miejsca. Do Wikidata importowane są miliony danych
bibliograficznych.
Codziennie przybywają nowe. W następnej fazie powstaną meta-dane i
oprogramowanie wykorzystujące cytowania w praktycznych
zastosowaniach.
Na obrazku powyżej widać, że artykuły naukowe stanowią ponad 40%
zawartości Wikidata.
Przyszło mi do głowy, żeby przenieść cytowania już zastosowane w
polskiej Wikipedii do Wikidata. Dlatego, żeby były już tam i żeby
gdy nadejdą rozwiązania techniczne móc je używać.
Szablony cytowania, wydają się proste i łatwe do sprawdzenia i
przeniesienia. Przecież jest to usystematyzowana i strukturyzowana
informacja o cytowaniach.
Po pierwszych próbach, okazało się to trudniejsze niż na pierwszy
rzut oka się to wydawało.
Wikidata (czyli w tłumaczeniu na polski
Wikidane) to moim zdaniem najbardziej wartościowy i
przyszłościowy projekt w Internecie.
Tak jak wizją przyświecającą Wikipedii stało się udostępnienie
wszystkim ogółu wiedzy ludzkości, tak Wikidata stanie się projektem
dotyczącym wiedzy o nieograniczonych możliwościach czyli
Wiedza2.
Wikidata i „infrastruktura” informatyczna wokół niej rozwinięta
przeniesie wszystkie projekty Wikimedia na nowy poziom, a poza tym
umożliwi cały szereg zastosowań, które obecnie są tylko w
zamierzeniach lub czekają na wymyślenie.
Tak jak Wikipedia zmieniła na zawsze oblicze Internetu, tak samo w
niedalekiej przyszłości Wikidata zmieni... właściwie nie wiemy jak
będzie wyglądało to coś co nazywamy dzisiaj Internetem.
Przemiany które zaczynają zmieniać oblicze projektów Wikimedia już
się dzieją.
Wikidata a Wikimedia Commons
Wikimedia Commons gigantyczna zbiornica danych
multimedialnych. Teraz dzięki (koordynacji z) Wikidata za pomocą
inicjatywy Structured Data zmienia się, dzięki
czemu 52 miliony plików multimedialnych będzie można lepiej
wyszukiwać, klasyfikować i w inny sposób wykorzystywać. Spróbujcie
teraz znaleźć coś konkretnego...
Wikicite
Wikicite czyli w zamyśle gigantyczna centralna baza
danych zawierająca (meta)dane potrzebne żeby uźródłowić wszystkie
informacje w Wikipediach i innych projektach pod egidą Wikimedia
Foundation.
Cała idea wymaga sporo czasu i pracy, żeby się ziściła, ale
wystarczy powiedzieć, że na prawie 55 mln jednostek informacji w
Wikidata, ok. 40 % to dane o artykułach naukowych, które służą
głównie do uźródławiania.
Sama idea Wikicite ma proponowane trzy zakresy o wzrastającym
rozmiarze danych i planowanych możliwości:
Wikicite S (small): tylko na potrzeby dla projektów Wikimedia
Wikicite M (medium): nie tylko na potrzeby projektów Wikimedia
Wikicite XL (extra large): bibliograficzna baza danych całej wiedzy
ludzkości
Nie wiadomo jak to finalnie ma wyglądać, być może zacznie się od
wariantu S.
Leksemy w Wikidata
Wikisłowniki czy Wiktionary przenoszą się też powoli do Wikidata.
Zaczęło się to w 2018 roku, kiedy pojawiły się nowe typy danych w
Wikidata:
słowa, frazy i sentencje, w wielu językach, które są z kolei
opisane też w wielu językach.
W Wikidata pojawiły się:
Leksemy (L)
Formy (F)
i Znaczenia (S).
Abstrakcyjna Wikipedia
Główny pomysłodawca Wikidata Denny Vrandečić chce oddzielić fakty
od warstwy lingwistycznej i przez to wyprodukować Wikipedię w
dowolnym języku. Zbiorowisko faktów będzie prawdopodobnie w
Wikidata. Więcej w publikacji Denny'ego pt. Toward an abstract
Wikipedia (plik PDF).
Mój mini-projekt zakładający analizę danych w polskiej Wikipedii
koncentrował się przypisach czyli materiałach źródłowych na które
powołuje się w nasza Wikipedia w hasłach.
Nieco dokładniej data mining polegał na wyciąganiu szablonów
cytowania.
Jednym z takich szablonów cytowania jest {{Cytuj stronę}}.
Szablon {{Cytuj
stronę}}
Ciekawym dla mnie było...
Do jakich serwisów internetowych
odwołuje się polska Wikipedia ?
Łączna ilość zliczonych wystąpień szablonu {{Cytuj stronę}}:
1758296
Do uźródłowienia merytorycznych treści w Wikipediach służą przypisy.
Aby tworzenie przypisów ułatwić i nadać im ustaloną strukturę,
wykorzystywana jest grupa szablonów określane nazwą szablonów cytowania.
Ważnym szablonem jest szablon o
nazwie Cytuj książkę, występujący w kodzie
wiki-tekstu jako {{Cytuj książkę|...}}
Ten szablon używamy, gdy informacje potwierdzające treść pierwotnie
pochodzą z publikacji książkowej (w wersji elektronicznej lub
nie).
Obecnie każda książka jest jednoznacznie identyfikowana przez
ISBN.
Tego identyfikatora użyli autorzy zbioru danych (dataset), dla
pozycji książkowych użytych w jakimkolwiek kontekście w polskiej
Wikipedii.
Ja natomiast, we wcześniejszym poście przedstawiłem 20 książek najczęściej występujących w
WP-PL w cytowaniach, na podstawie tego zbioru danych.
Teraz przedstawiam takie samo zestawienie, ale stworzone na
podstawie mojego własnego zbioru danych.
Przyjęta metodologia była nieco odmienna, gdyż ja wyciągnąłem
wszystkie szablony "Cytuj książkę” z haseł, a z nich następnie
powyciągałem ISBNy.
Poza tym użyłem nowszego dumpa XML polskiej Wikipedii, bo z listopada
2018, a nie z marca 2018.
Pewna ilość szablonów zawierających jakąś wartość w parametrze
"isbn" została odrzucona, ponieważ zawierały nieprawidłowe dane
(np. ciągi znaków takie jak: "brak" lub "wtedy nie było
adnotacji o ISBN").
Wyniki analizy
Cichocki, Włodzimierz Polskie nazewnictwo ssaków
świata (Polish names of mammals of the world), Muzeum i
Instytut Zoologii PAN, Warszawa, 2015, ISBN 978-83-88147-15-9, OCLC
922215069 = 3083
Paryska, Zofia Wielka encyklopedia tatrzańska,
Wydawnictwo Górskie, Poronin, 1995, ISBN 83-7104-009-1, OCLC
35208429 = 2578
Polak, Bogusław Polskie formacje graniczne 1918-1939 :
Straż Graniczna 1918- 1939 : dokumenty organizacyjne : wybór
źródeł, Wydawnictwo Uczelniane Politechniki
Koszalińskiej, Koszalin ,1999, ISBN 83-87424-77-3, OCLC 49399163
= 1969
Wojewoda, Władysław Checklist of Polish
larger Basidiomycetes (Krytyczna lista wielkoowocnikowych
grzybów podstawkowych Polski), W. Szafer Institute of Botany,
Polish Academy of Sciences, Kraków, 2003, ISBN 83-89648-09-1, OCLC
62368937 = 1571
Dominiczak, Henryk Granice państwa i ich ochrona na
przestrzeni dziejów : 966-1996, Wydawnictwo Bellona,
Warszawa, 1997, ISBN 83-11-08618-4, OCLC 37244743 =1390
Kurzyński, Henryk Historia finałów Lekkoatletycznych
Mistrzostw Polski 1920-2007 : konkurencje męskie,
KAdruk Komisja Statystyczna PZLA, Szczecin-Warszawa, 2008, ISBN
978-83-61233-20-6, OCLC 751207980 = 1228
Rutkowski, Lucjan Klucz do oznaczania roślin
naczyniowych Polski niżowej, Wydawnictwo Naukowe PWN,
Warszawa, 2007, ISBN 83-01-14342-8, OCLC 183208377 =
1138
Choiński, Adam Katalog jezior Polski,
Wydawnictwo Naukowe UAM, Poznań, 2006, ISBN 83-232-1732-7, OCLC
169954726 =1039
Matuszkiewicz, Władysław Przewodnik do oznaczania
zbiorowisk roślinnych Polski, Wydawnictwo Naukowe PWN,
2007, Warszawa, ISBN 83-01-14439-4, OCLC 214323325 =
988
Kula, Henryk Polska straż graniczna w latach
1928-1939, Wydawnictwo Bellona, 1994, Warszawa, ISBN
83-110-826-71 =980
Kondracki, Jerzy Geografia regionalna Polski,
Wydawnictwo Naukowe PWN, Warszawa, 1998, ISBN 83-01-12479-2, OCLC
40893735 = 877
Mirek, Zbigniew Red list of plants and fungi in
Poland (Czerwona lista roślin i grzybów Polski), W.
Szafer Institute of Botany, Polish Academy of Sciences, Kraków,
2006, ISBN 83-89648-38-5, OCLC 78225357 = 861
Chodkowski, Andrzej Encyklopedia muzyki,
Wydawnictwo Naukowe PWN, Warszawa, 2007, ISBN 8301113901 =
857
Fros, Henryk i Sowa, Franciszek
Księga imion i świętych. T. 6, W-Z, Kraków,
Wydawnictwo WAM - Księża Jezuici, 2007, ISBN 9788373187368 =
802
Pawłowska, Ewa Hydronimy, Główny Urząd Geodezji i
Kartografii,Warszawa, 2006, ISBN 83-239-9607-5, OCLC 749337946 =
778
Mirek, Zbigniew Czerwona księga Karpat Polskich : rośliny
naczyniowe, Instytut Botaniki im. W. Szafera PAN, Kraków,
2008, ISBN 978-83-89648-71-6, OCLC 401780346 = 750
Januszewski, Jarosław Tatry i Podtatrze : atlas satelitarny,
1:15 000, Geosystems Polska, Warszawa, 2005, ISBN
83-909352-2-8, OCLC 181637523 = 748
Kaźmierczakowa, Róża Polska
czerwona lista roślin paprotników i roślin kwiatowych
(Polish red list of pteridophytes and flowering plants), Instytut
Ochrony Przyrody, Polska Akademia Nauk, 2016,ISBN 9788361191889,
OCLC 982380143 = 730
Sula, Marek Rejon Giewontu i Czerwonych Wierchów : mapa
turystyczna 1:20 000 (Tourist map, Touristenkarte, Turistická
mapa), WiT, Piwniczna Zdrój, 2006, ISBN 83-89580-00-4, OCLC
839072663 = 721
Gajl, Tadeusz Herbarz polski od średniowiecza do XX wieku :
ponad 4500 herbów szlacheckich 37 tysięcy nazwisk 55 tysięcy
rodów, L&L, Gdańsk, 2007, ISBN 978-83-60597-10-1, OCLC
233447252 = 719
Wnioski
Bardzo podobna lista, w zasadzie prawie to samo. Drobne
przesunięcia pod względem częstości z poprzedniej listy i 2 nowe pozycje
(zaznaczone na czerwono).
Najczęstsza książka została użyta w ponad 3000 szablonów
"Cytuj książkę"
Zestawienie nie obejmuje wszystkich książek użytych w
cytowaniach
Wiele szablonów "Cytuj książkę" nie zawiera ISBNa, ani
OCLC ID (ponad 200.000 szablonów)
Sporo szablonów "Cytuj książkę" zawiera nieprawidłowe
dane jako wartość parametru isbn
Pewna ilość szablonów wymaga poprawy ręcznej, zdecydowana
większość może być poprawiona za pomocą botów
W serwisie naukowym Figshare został opublikowany zestaw danych (dataset)
pn. Citations with identifiers in Wikipedia, którego
autorami są: Aaron Halfaker,
Bahodir Mansurov, Miriam Redi i Dario
Taraborelli.
Copyright:
Mediawiki developers CC-SA 3.0
Te dane zawierają także cytowania źródeł w polskiej Wikipedii na
stan z dnia 1 marca 2018 roku. Chociaż dane zawierają sporą ilość
błędów, to dają jednak pogląd na temat najczęściej używanych w
polskiej wersji Wikipedii źródeł.
Poniżej przedstawiam 20 najczęściej cytowanych źródeł
książkowych.
Są to: publikacje biologiczne, geograficzne i związane z siłami
zbrojnymi.
Cichocki, Włodzimierz Polskie nazewnictwo ssaków
świata (Polish names of mammals of the world), Muzeum i
Instytut Zoologii PAN, Warszawa, 2015, ISBN 978-83-88147-15-9, OCLC
922215069
Paryska, Zofia Wielka encyklopedia tatrzańska,
Wydawnictwo Górskie, Poronin, 1995, ISBN 83-7104-009-1, OCLC
35208429
Polak, Bogusław Polskie formacje graniczne 1918-1939 :
Straż Graniczna 1918- 1939 : dokumenty organizacyjne : wybór
źródeł, Wydawnictwo Uczelniane Politechniki
Koszalińskiej, Koszalin ,1999, ISBN 83-87424-77-3, OCLC
49399163
Wojewoda, Władysław Checklist of Polish larger
Basidiomycetes (Krytyczna lista wielkoowocnikowych grzybów
podstawkowych Polski), W. Szafer Institute of Botany, Polish
Academy of Sciences, Kraków, 2003, ISBN 83-89648-09-1, OCLC
62368937
Dominiczak, Henryk Granice państwa i ich ochrona na
przestrzeni dziejów : 966-1996, Wydawnictwo Bellona,
Warszawa, 1997, ISBN 83-11-08618-4, OCLC 37244743
Kula, Henryk Polska straż graniczna w latach
1928-1939, Wydawnictwo Bellona, 1994, Warszawa, ISBN
83-110-826-71
Mirek, Zbigniew Red list of plants and fungi in
Poland (Czerwona lista roślin i grzybów Polski), W.
Szafer Institute of Botany, Polish Academy of Sciences, Kraków,
2006, ISBN 83-89648-38-5, OCLC 78225357
Pawłowska, Ewa Hydronimy, Główny Urząd Geodezji
i Kartografii,Warszawa, 2006, ISBN 83-239-9607-5, OCLC
749337946
Matuszkiewicz, Władysław Przewodnik do oznaczania
zbiorowisk roślinnych Polski, Wydawnictwo Naukowe PWN,
2007, Warszawa, ISBN 83-01-14439-4, OCLC 214323325
Januszewski, Jarosław Tatry i Podtatrze : atlas
satelitarny, 1:15 000 Geosystems Polska, Warszawa, 2005,
ISBN 83-909352-2-8, OCLC 181637523
Sula, Marek Rejon Giewontu i Czerwonych Wierchów : mapa
turystyczna 1:20 000 (Tourist map, Touristenkarte,
Turistická mapa), WiT, Piwniczna Zdrój, 2006, ISBN
83-89580-00-4, OCLC 839072663
Kurzyński, Henryk Historia finałów Lekkoatletycznych
Mistrzostw Polski 1920-2007 : konkurencje męskie, KAdruk
Komisja Statystyczna PZLA, Szczecin-Warszawa, 2008, ISBN
978-83-61233-20-6, OCLC 751207980
Kondracki, Jerzy Geografia regionalna Polski,
Wydawnictwo Naukowe PWN, Warszawa, 1998, ISBN 83-01-12479-2, OCLC
40893735
Mirek, Zbigniew Czerwona księga Karpat Polskich :
rośliny naczyniowe, Instytut Botaniki im. W. Szafera PAN,
Kraków, 2008, ISBN 978-83-89648-71-6, OCLC 401780346
Gajl, Tadeusz Herbarz polski od średniowiecza do XX
wieku : ponad 4500 herbów szlacheckich 37 tysięcy nazwisk 55
tysięcy rodów, L&L, Gdańsk, 2007, ISBN
978-83-60597-10-1, OCLC 233447252
Rutkowski, Lucjan Klucz do oznaczania roślin
naczyniowych Polski niżowej, Wydawnictwo Naukowe PWN,
Warszawa, 2007, ISBN 83-01-14342-8, OCLC 183208377
Cheers, Gordon Botanica : ilustrowana, w alfabetycznym
układzie, opisuje ponad 10 000 roślin ogrodowych,
Könemann, Germany, 2005, ISBN 3-8331-1916-0, OCLC 271991134
Choiński, Adam Katalog jezior Polski,
Wydawnictwo Naukowe UAM, Poznań, 2006, ISBN 83-232-1732-7, OCLC
169954726
Fałtynowicz, Wiesław The lichens, lichenicolous and
allied fungi of Poland--an annotated checklist (Krytyczna
lista porostów i grzybów naporostowych Polski), W. Szafer
Institute of Botany, Polish Academy of Sciences, Kraków, 2003,
ISBN 83-89648-06-7,OCLC 56564942
Kajetanowicz, Jerzy Polskie wojska lądowe 1945-1960 :
skład bojowy, struktury organizacyjne i uzbrojenie,
Europejskie Centrum Edukacyjne, Toruń, 2005, ISBN 83-88089-67-6,
OCLC 749665942
Z jednej strony wydaje się, że nie są to dobre źródła i że nie
powinny znaleźć się w encyklopedii.
Ale z drugiej strony skąd brać merytoryczne informacje do haseł o
celebrytach ?
Może te serwisy są jednak lepsze niż nic ?
Jak to jest w innych wersjach językowych Wikipedii ? Czy nie
posługują się też takimi serwisami czy wydawnictwami (News of the World) w hasłach o celebrytach ?
Jedną z podstawowych wartości Wikipedii jest jej
wiarygodność.
Wiarygodność oparta na przypisach czyli źródłach dla
(prawie) każdej merytorycznej treści podawanej w hasłach
Wikipedii.
Cytowania są oznaczone za pomocą tagów (znaczników)
ref.
Aby ułatwić wstawianie treści cytowań stworzono grupę szablonów
cytowania.
Nazwa szablonu
Rodzaj źródła
{{Cytuj grę komputerową}}
gry komputerowe
{{Cytuj książkę}}
książki
{{Cytuj odcinek}}
odcinki programów
{{Cytuj pismo}}
gazety, czasopisma
{{Cytuj stronę}}
strony internetowe
{{Cytuj}}
uniwersalny
W angielskiej Wikipedii mają trochę więcej szablonów "Cytuj" i o
nieco innej funkcji.
Nazwa szablonu
Rodzaj źródła
{{cite video game}}
gry komputerowe
{{cite book}}
książki
{{cite journal}}
artykuł naukowy
{{cite episode}}
odcinki programów
{{cite news}}
gazety, czasopisma
{{cite web}}
strony internetowe
{{cite album notes}}
okładka płyty itp.
{{cite AV notes}}
j.w + wideo, DVD
{{cite comic}}
komiks
{{comic strip reference}}
komiks+
{{cite conference}}
konferencja nauk.
{{cite court}}
sprawa sądowa
{{cite encyclopedia}}
encyklopedia
{{cite mailing list}}
lista dyskusyjna
{{cite map}}
mapa
{{cite newsgroup}}
grupa dyskusyjna
{{citation}}
patent i inne
{{cite press release}}
komunikat dla prasy
{{cite thesis}}
praca magisterska
Największy problem dla mnie osobiście stanowi nierównoważność
polskiego {{cytuj pismo}} z angielskim {{cite
journal}}.
Do polskiego wsadzone jest oprócz artykułów naukowych
opublikowanych w czasopismach naukowych, cała masa innych rzeczy
przez to, że jest on przeznaczony dla wszelkich druków
periodycznych.
Powoduje to często pomylenie pojęć. Dla niektórych pismem jest
książka lub strona internetowa.
Źródła w 1,3 mln haseł polskiej
Wikipedii
Dla mnie jako lekarza (wiarygodne) źródła w książkach i artykułach
naukowych to oczywistość.
EBM, meta-analizy i podwójnie zaślepione randomizowane badania to rzeczy, które świadczą o
jakości informacji medycznej.
Wpadł mi kiedyś do głowy pomysł, żeby przyjrzeć się uźródłowieniu
polskiej Wikipedii. Wszystko w powiązaniu z bardzo cenną i
przyszłościową inicjatywą WikiCite.
Postanowiłem zabrać głos na kanwie
reakcji wikipedystów, czytelników i mediów, jakie nastąpiły w
trakcie i po wygaszeniu polskojęzycznej Wikipedii. Omówię poważny
problem i nie będzie to wpis o tym, kto gdzie popełnił błąd i w
jakim trybie ma zapłacić.
Parlament Europejski miał
zdecydować w bardzo ważnej sprawie, w której nie przewija się nazwa
„Wikipedia”. Ilu wikipedystów wiedziało, że ta sprawa jest ważna,
że rozgrywa się teraz, że nas dotyczy i co należy zrobić? Ile osób
zaplanowało akcję i w odpowiednim czasie odpowiednio
zareagowało?
Zdjęcie nie przedstawia litery „O”. J. Poe, Number zero
decoration, CC BY 2.0.
Nawet tytularni specjaliści tacy
jak ja, hobbystyczni jak Polimerek i funkcyjni jak Aegis nie
zadziałali odpowiednio wcześnie. Każdy z wymienionych miał powody,
których nie będę omawiał ze względu na poszanowanie prywatności.
Dość powiedzieć, że pracuję na 1,5 etatu, a pozostali dwaj to
były i obecny prezes zarządu Wikimedia Polska (ile prezes ma na
głowie, dowiecie się
stąd i stąd).
Aha, Natalia, specjalistka ds. wspierania społeczności, nie ma
obowiązku orientować się w prawie. A wikipedyści-prawnicy pracują
na prawie obowiązującym i niekoniecznie śledzą projekty zmian.
Efekt jest taki, że wielu
wikipedystów nie wie, na czym dokładnie polega sprawa tzw. ACTA
2 (będę używał tej nazwy, bo jest krótka). Poziom
poinformowania jest troszeczkę lepszy niż wśród ogółu społeczeństwa
(wskazówka jednak podryguje z pozycji zerowej), ale
wzajemnego kompetentnego informowania się jest zero (niemal, tzn. w
stosunku do potrzeb).
W czasie wolnym od pracy, jeśli
mogę zająć się ACTA 2, to czytam projekt dyrektywy,
stanowiska komisji, artykuły prasowe, wpisy na blogach, odświeżam
sobie pamięć na temat dyrektywy 2001/29/WE, sprawdzam orzecznictwo,
rozmawiam ze specjalistką z Centrum Cyfrowego. To wyjątkowo, w
przeddzień występu w radiu. W inne dni spotykam się ze znajomymi
albo idę na rower, robię zakupy albo odbieram
korespondencję, jem kolację, rozmasowuję bolące mięśnie karku
i idę spać. Nie brzmi jak Wikimedia, prawda?
Stanowczo brakuje mi czasu na
pisanie opinii prawnej dla społeczności wikimedian, na tworzenie
infografik, a przynajmniej wykresów czy tabelek, na odpowiadanie na
pytania (to byłoby fajne! ACTA 2 Q&A, ACTA 2
FAQ), na rozpowszechnianie linków do kontentu „kształcenia
ustawicznego dla wikimedian”.
Coś takiego powinna robić osoba
współpracująca z Wikimedia Polska na podstawie umowy, powiedzmy
umowy zlecenia, albo umowy o dzieło z listą zadań do wykonania w
razie sytuacji X. Taka osoba powinna też obserwować sytuację,
ostrzegać w odpowiednim czasie i z wyprzedzeniem tworzyć teksty,
które można by rozesłać w razie określonej zmiany sytuacji.
Przykładowo można było z góry napisać dwa teksty: jeden, który
poszedł do mediów i do społeczności, kiedy Parlament odrzucił
rekomendacje komisji JURI, i drugi, na wypadek, gdyby rekomendacje
zostały przyjęte.
Nie uważam, że potrzeba na to pół
etatu, ani nawet ćwierć na stałe. Model współpracy mógłby być
podobny do współpracy z agencją PR – w czasie spokoju mamy
pogadanki, Q&A i szkolenia, a w czasie mobilizacji przechodzimy
w tryb zarządzania kryzysowego.
Nie czuję się kompetentny, żeby
temu sprostać. Być może to, co napisałem, jest nie do zrealizowania
z kimś innym niż z całą kancelarią prawną. Być może nie stać
Stowarzyszenia na taką współpracę. Być może na początek trzeba
obniżyć wymagania. Ale przygoda z ACTA 2 „skończy
się” wtedy, gdy Polska implementuje uchwaloną dyrektywę. Najpierw
odbędzie się plenarna dyskusja Parlamentu, o którą właśnie
walczyliśmy, i negocjacje Parlamentu z Radą. Za ok. pół roku
uchwalenie dyrektywy, po dłuższym czasie implementacja. Mamy może
rok, może 2–3. To wystarczająco długo, żeby Stowarzyszenie
zainwestowało w advocacy. Bo że temat jest wystarczająco
ważny, to niestety nieoczywiste, ale „wierzcie mi, jestem
prawnikiem”.
Nieobecni nie mają racji –
szczególnie wtedy, kiedy sami rezygnują z obecności. Nieznajomość
reguł gry szkodzi – a reguły gry zaraz będą ustalane. Mamy
okazję, żeby dobrze przygotować się na nadchodzące zmiany, zanim te
wejdą w życie. Ta okazja nazywa się: 135 wolnych miejsc w
grupach roboczych.
Znaczenie fazy 1 (2017 r.) dla
procesu ustalania strategii
Pierwsza
faza, która miała miejsce w 2017, była pomocnicza, wstępna.
Służyła „rozpoznaniu terenu” i wytworzeniu materiałów potrzebnych w
dalszych pracach. Z perspektywy roboczej, wszystkie dyskusje, które
toczyliśmy,
wszystkie raporty, które opracowano na koniec, są jedynie
dokumentacją potrzebną do fazy 2. Tym bardziej należy je znać,
ponieważ wtedy będzie nam łatwiej uczestniczyć w fazie 2. A to
właśnie w fazie 2 będą zapadały decyzje. Mam nadzieję, że
przekonałem do przeczytania raportów.
Twórcy procesu strategicznego
wyszli ze słusznego założenia, że podstawowym kapitałem ruchu
Wikimedia jest społeczność wolontariuszy. Oprócz nich mamy też np.
liderów, Wikidane i przepustowe serwery, ale przyszłość powinniśmy
budować na ludziach. Dlatego w 1 fazie trzeba było się zorientować,
co ludzie sądzą i czego chcą. Potem trzeba to było sprowadzić do
wspólnego mianownika (Kierunek).
Na tym – ale głównie na wzmiankowanych raportach – można
budować decyzje dotyczące różnych obszarów działalności ruchu
Wikimedia.
Konstrukcja fazy 2 (2018–2019
r.)
Ruch
Wikimedia jest zróżnicowany wewnętrznie, np.
VisualEditor, GLAM i zarządzanie
chapterem
mają ze sobą mało wspólnego. Strategiczne decyzje muszą dotyczyć
różnych, oddzielnych obszarów. Nie ma sposobu, żeby jedna grupa
ludzi wzięła na siebie ustalenie planu dla wszystkich. Oczywiście
te strategiczne decyzje muszą być zharmonizowane, żeby np. nie
były ze sobą sprzeczne. Niemniej jednak osoba decydująca o
przyszłości oprogramowania nie musi decydować o przyszłości
partnerstw GLAM itp.
Wydzielono więc 9 obszarów tematycznych. Nad każdym będzie
pracowała jedna grupa robocza, złożona z ok. 10–15 osób. 9 ×
15 = 135. Członkowie grup powinni wywodzić się z różnych
środowisk:
z Wikimedia Foundation i
afiliantów (takich jak Wikimedia Polska) rozmiarów i typów
(czaptery, grupy użytkowników, organizacje tematyczne):
członkowie zarządów,
pracownicy,
ze społeczności online:
z różnych projektów,
z różnych języków,
nie tylko piszący artykuły, ale
także fotografowie i twórcy oprogramowania,
osobne grupy tworzą dyrektorzy
wykonawczy i prezesi zarządów,
z regionalnych środowisk
współpracujących (w Polsce: KOED?),
z nieformalnych zorganizowanych
grup.
Te grupy będą wypracowywały
konkretne decyzje. Może być tak, że kraje członkowskie UE będące
byłymi demoludami zostaną wrzucone do tej samej grupy ekonomicznej,
co tzw. stara Unia. I będzie rekomendacja, aby WMF przestała
fundować afiliantów z USA i UE (skoro to bogate państwa). Albo taka
rekomendacja, że nie może być banerów w UE, z których nic nie idzie
do Afryki i Azji (jak jest z polskim OPP). Nie twierdzę, że tak
będzie, ale moja wyobraźnia obejmuje takie opcje.
Ale: trzeba pamiętać, że członkowie
grup roboczych mają kierować się dobrem całego ruchu Wikimedia, nie
partykularnym. Trzeba więc mądrze wnosić swoje doświadczenie (które
stanowi o bogactwie Wikimediów) ale nie lobbować na jego rzecz.
Od członków grup roboczych wymaga
się poświęcenia średnio 5 godzin tygodniowo przez cały okres ich
pracy. Jeśli to dla Was za dużo, żeby zgłosić swoją kandydaturę, to
zmieńcie priorytety. To brutalne, ale zmieńcie je,
zanim priorytety określone bez Waszego głosu nie zmienią Wam życia
na takie, jakiego nie chcecie.
Dla tych, którzy – jak
ja – wolą motywację pozytywną: jeśli dołączycie do grup
roboczych, podzielicie się swoją wiedzą i umiejętnościami ze
światem. Dowiecie się, jak lepiej działać w Wikimediach. Poznacie
naprawdę ciekawych ludzi, może nawet nawiążecie przyjaźnie.
Będziecie blisko ważnych wydarzeń. Poprawicie swój angielski. Ta
przygoda Was ubogaci.
Oto planowana oś czasu pracy grup
roboczych (mogą pojawić się poślizgi):
Oś czasu pracy w 2 fazie (od czerwca 2018 do czerwca
2019). Anna Lena Schiller, CC BY-SA 4.0
W następnym tekście opiszę swoje
spostrzeżenia z 1 fazy (z 2017 r.). Osobno też o tym, dlaczego
uważam, że Michał Buczyński na stanowisku prezesa zarządu WMPL to
właściwa osoba na właściwym miejscu i na jakie projekty,
szczególnie zbieżne z Kierunkiem strategicznym, może postawić
WMPL.
W grudniu 2017 ukazało się wiele
nowych artykułów autorstwa studentów: położnictwo, prawo, chyba coś
jeszcze. Takie akcje są organizowane od lat. Ten wpis dedykuję
studentom, którzy chcą na szybko dowiedzieć się jak napisać
poprawny artykuł dotyczący prawa, który zostanie bez problemu
zaakceptowany. Staram się pisać krótko i uwzględnić jak najwięcej
często popełnianych błędów. Z góry przepraszam, że nie ma
spisu treści. Kosztowałoby mnie to 25 dolarów miesięcznie
Mała uwaga na wstępie
Piszę o dobrych, bezpiecznych
praktykach. Zachęcam do pisania przemyślanych, kompletnych
artykułów (na poziomie krótkiego odczytu popularnonaukowego). Nie
dziwcie się, że niektóre istniejące artykuły w Wikipedii są
wybrakowane albo niekonsekwentne. Od ok. 8 lat stawiamy na
jakość, ale jest jeszcze wiele treści powstałych w okresie parcia
na ilość. Sukcesywnie je poprawiamy i nie mogą być one wzorem do
naśladowania.
Zrzuty ekranu pochodzą z mojego
artykułu o teście
trójstopniowym, który polecam jako wzór.
Krótka forma, też mojego autorstwa: copyright.
Średnia długość, w większości mój: prawo cytatu.
Krok 0: Zanim zaczniemy pisać. Zasady encyklopedii
Encyklopedia powszechna
Studenci prawa lubią zasady
Encyklopedia jest źródłem
pierwszego kontaktu. Nie piszemy wywodu naukowego ani praktycznego
poradnika. Opisujemy pojęcia (norma prawna,
centralny organ administracji, pozew). Zamiast „Angielski proces karny w ujęciu
prawnoporównawczym” opisujemy „Postępowanie karne (Anglia)”, a tam
powinna się też znaleźć np. historia tego procesu. Komparatystyczne
eseje nie są encyklopedyczne. Opisanie obecnych źródeł czy
obecnych funkcji danej gałęzi prawa powinno być w artykule o tej
gałęzi, a nie w osobnych artykułach. Z kolei historia czy filozofia
danej gałęzi prawa zasługuje na osobny artykuł.
Piszemy encyklopedię nie tylko
prawniczą. Nie zawłaszczamy tematu ujęciem
prawniczym. Istnieje wiele tematów, które można omówić
równorzędnie pod kątem prawniczym, ekonomicznym, socjologicznym,
politologicznym lub filozoficznym. Na plus jest dodanie np.
statystyk socjologicznych. Jeżeli w ujęciu prawniczym dane pojęcie
ma osobne znaczenie, dobrze jest utworzyć artykuł pod hasłem
„nasz temat (prawo)”, jak np.
„rzecz
(prawo)”.
Piszemy ponadtymczasowo.
Nie skupiamy się na obecnym stanie rzeczy.
Równorzędnie do stanu obecnego, a nie tylko porównawczo, możemy
opisać historię. Spisy aktualnych źródeł danego prawa są usuwane.
Unikamy takich sformułowań jak „w obecnym stanie prawnym”.
Piszemy encyklopedię po
polsku, ale nie polską. W encyklopedii równorzędnie do
prawa polskiego, a nie tylko porównawczo, możemy opisać dane
zagadnienie w innych systemach prawnych. Prawo polskie opiszemy
poniżej prawa belgijskiego. Zamiast: „Zabójstwo – typ
przestępstwa określony w art. 148 k.k.” piszemy
„Zabójstwo –
przestępstwo polegające na zabiciu człowieka”.
Nasz własny tekst…
Piszemy na podstawie tekstów
prawniczych, a nie tekstów prawnych. Nie cytujemy tekstów aktów
prawnych, tylko do nich odsyłamy (zob. sekcję dotyczącą
przypisów).
Inspiracja – OK, „kopiuj-wklej” – nie OK
Zanim coś napiszemy, gromadzimy
przynajmniej 2–3 książki na dany temat, raczej różnych
autorów. Szanujemy ich prawa autorskie. Kompilujemy to, co
napisali i piszemy swoimi słowami. Nie powtarzamy całych zdań czy
sformułowań (chyba że w cytacie). Staramy się nie powtarzać
kolejności argumentów jednego autora, ponieważ do samego doboru i
kolejności informacji (w tym: wyliczeń i spisu treści) też mogą
istnieć prawa autorskie, których nie wolno naruszyć.
Podsumowując: czytelnik ma mieć
wrażenie, że tego tekstu jeszcze nie czytał.
…ale żadnych własnych informacji
Piszemy wyłącznie to, co inni
opublikowali w rzetelnych źródłach. Istnieją źródła bardziej i
mniej rzetelne. Na pierwszym miejscu są teksty doktryny: książki,
monografie, komentarze, czasopisma naukowe, księgi jubileuszowe.
Ogólnopolska prasa typu „Dziennik Gazeta Prawna” też może
być. Omijamy blogi praktyków prawa.
Po każdej
informacji wstawiamy przypis z adresem bibliograficznym do źródła
(zob. sekcję dotyczącą przypisów). Żeby uprościć pisanie przypisów,
polecam przypisy harwardzkie, w których podajemy tylko nazwisko,
rok i stronę. Pełen adres bibliograficzny możemy wtedy umieścić w
rozdziale „Bibliografia”, bezpośrednio pod przypisami.
Podsumowując: specjalista ma mieć
wrażenie, że niczego nowego się od nas nie dowiedział.
Krok 1: Zaczynamy pisać. Układ tekstu i styl
Układ tekstu
Zaczynamy od hasła, czyli tego, co
jest w nazwie artykułu. Następnie myślnik i definicja. Jak
informują
nasze helpy, definicja „powinna być czytelna, niezbyt długa ani
szczegółowa, napisana przystępnym językiem, umożliwiająca
czytelnikowi szybkie dowiedzenie się, o co
chodzi, co to jest bez czytania
rozwinięcia”.
Następny akapit to wstęp, który
wprowadza do tematyki artykułu i streszcza jego
zawartość. Dobry wstęp ma skłonić do przeczytania dalszej
części artykułu poprzez podsumowanie kluczowych kwestii. Nie musimy
tam wstawiać przypisów, o ile te same informacje pojawią się
dalej.
Dalej piszemy kolejne rozdziały,
rozpoczęte nagłówkami. Dzielimy tekst na mniej więcej równe
rozdziały, każda myśl w osobnym akapicie. Akapity powinien łączyć
spójny tok wypowiedzi. Unikamy tworzenia akapitów jednozdaniowych i
rozdziałów jednoakapitowych. Na tym etapie warto wstawiać przypisy,
albo zaznaczać sobie gdzie mają być i do czego (jeżeli wolimy je
wstawić po napisaniu tekstu).
Staramy się pisać
zdaniami. Wypunktowanie, numerowanie, tabele itd. to
dodatki, a nie zamienniki zdań.
Piszemy starannie, budujemy poprawne zdania,
uważamy na znaki interpunkcyjne (szczególnie przecinki, apostrofy,
myślniki).
Styl
Stylistycznie encyklopedia to pustynia. Jak okiem sięgnąć,
żadnych upiększeń.
Piszemy prostym, suchym językiem
przystępny tekst edukacyjny, informacyjny:
nie używamy sformułowań
łacińskich takich jak sui generis, prima facie, ergo, primo, in casu, tempore criminis – bo nie
każdy czytelnik zna łacinę. Lepiej: „swego rodzaju”, „na pierwszy rzut oka”, „więc”, „po pierwsze”, „w danym przypadku”, „w czasie popełnienia przestępstwa”;
bardzo formalne słowa takie
jak „albowiem/bowiem”
zastępujemy prostszymi typu „ponieważ”;
unikamy inwersji i strony
biernej: zamiast „orzekana mogła być” lepiej „mogła być orzekana”, a
nawet „sąd mógł
orzec”;
odrzucamy styl
specjalistyczny: nie piszemy o sporach w doktrynie (tylko o
„kwestiach, co do których naukowcy mają różne poglądy”). Zamiast
„doktryna i orzecznictwo”
lepiej napisać „naukowcy i
sądy”, zamiast „ma
charakter materialnoprawny” piszemy „jest materialnoprawny”, zamiast
„do dnia 1
stycznia” – „do 1 stycznia”;
unikamy wyrazów pochodzenia obcego
oznaczających prawnicze pojęcia, jeżeli mamy polskie odpowiedniki,
np. zamiast „ekskulpacja”
piszemy „wykazanie braku
winy” (chyba że piszemy artykuł o ekskulpacji);
unikamy wtrąceń
takich jak „można/należy zauważyć/stwierdzić/wskazać”, „ciekawym/istotnym aspektem jest” – bo one dodają
tekst, a nie dodają informacji;
nie piszemy „można wyróżnić” albo „wyróżniamy”, tylko „wyróżnia się” – bo tylko referujemy
co kto inny wyróżnił (zob. sekcję dotyczącą zasad). Ponadto w
encyklopedii nie ma „my autor” ani „my: autor i czytelnicy”;
odrzucamy emfazę, przymiotniki i przysłówki
typu „oczywiście”,
„niewątpliwie”. Takie
jak „wyjątkowo” stosujemy oszczędnie, np. gdy piszemy o
wyjątku w opozycji do zasady. Natomiast kiedy chcemy coś podkreślić
sami – nie podkreślamy.
Krok 2: Przypisy. Gdzie i jak je wstawić
Liczba przypisów
Przypominam, przypis
bibliograficzny do źródła wstawiamy po każdej
informacji. Przed kropką kończącą zdanie, przed nawiasem kończącym
wtrącenie. Jeżeli napisaliśmy cały akapit na podstawie treści z tej
samej strony tej samej książki, wystarczy jeden przypis na końcu
akapitu. Ale przypisowe skąpstwo ma granice: akapity nie mogą być
za długie, bo takie się źle czyta. Gdy dzielimy akapit z jednym
przypisem, powstaje nowy, który na końcu nie ma przypisu. Tak więc
rozważnie. Najlepiej, gdy w akapicie są treści z różnych źródeł,
wtedy jest kilka przypisów i widać, do którego momentu informacja
jest skąd.
Nie stosujemy op. cit. ani
ibidem. Poniżej opiszę wstawianie przypisów do nowych
pozycji i ponowne wstawianie do tych samych.
Wstawianie przypisu: książki
Jeżeli źródłem jest książka, to
podajemy numer konkretnej strony. Do cytowania książek polecam
wspomniany szablon odn i przypisy harwardzkie. Szablony wstawiamy z
menu „Wstaw”:
Jeżeli chcemy ponownie wstawić
przypis do tej samej książki, kopiujemy znaczek przypisu i wklejamy
go tam, gdzie chcemy go mieć:
W razie potrzeby zmieniamy numer strony.
Wstawianie przypisu: inne
Inne pozycje bibliograficzne,
oprócz aktów normatywnych – np. publikacje elektroniczne z LEX-a,
strony internetowe, wyroki, do których nie mamy adresu URL –
cytujemy za pomocą menu „Przypis”. Do cytowania stron
internetowych i publikacji mających DOI używamy
zakładki „Automatycznie”, a do cytowania artykułów z czasopism
i wszystkiego tego, co nie działa automatycznie –
zakładki „Ręcznie” → opcji „Podaj źródło”:
Jeżeli chcemy wstawić przypis do
tej samej pozycji, to używamy zakładki „Użyj istniejącego”:
Wstawianie przypisu: akty normatywne
Przypominam: nie cytujemy treści
przepisów (zob. sekcję dotyczącą zasad). Kiedy wspomnimy o
ustawie czy o przepisie, wtedy w przypisie podajemy dany akt wraz z
miejscem publikacji. Ale nie wszystko wpisujemy jako zwykły tekst.
Dziennik Ustaw, EUR-Lex czy Monitor Polski mają swoje szablony,
które formatują tekst i wstawiają link do danego aktu. Przykładowo
przypis do ustawy o prawie autorskim wstawiamy tak:
wybieramy menu „Przypis” → zakładka „Ręcznie” → opcja „Zwykły
wygląd”,
w polu wpisujemy Ustawa z dnia 4 lutego 1994 r. o prawie
autorskim i prawach pokrewnych,
otwieramy nawias i w tym samym oknie wybieramy „Wstaw”
→ „Szablon” → wpisujemy dziennik ustaw i
uzupełniamy zgodnie ze wskazówkami: rok 1994, numer
24, pozycja 83. Klikamy „Wstaw”,
dopisujemy „ze zm.”, zamykamy nawias, kończymy kropką
i „Wstaw”.
Wtedy przypis wygląda tak:
Pamiętajmy o takich drobiazgach jak
kropki na końcu przypisów i „ze zm.”, jeżeli ustawa była
nowelizowana. Starsze polskie ustawy mają rok, numer i pozycję,
nowsze tylko rok i pozycję.
Krok 3: Wikizacja, czyli Wikipediowe formatowanie
Na koniec można zająć się
formatowaniem:
hasło (nazwę
artykułu, pierwszą część definicji) pogrubiamy (ikonka A albo
Ctrl+B). Nie pogrubiamy niczego poza hasłem i tylko w
definicji;
linkujemy pojęcia
(ikonka połączonych ogniw albo Ctrl+K). Nie wstawiamy linków
nagłówkach. Nie boimy się linkować do jeszcze nieopisanych pojęć. W
polu, w którym wyszukujemy stronę do podlinkowania, piszemy jej
nazwę:
formatujemy nagłówki. Korzystamy z
opcji „Podstawowy nagłówek rozdziału” i w razie potrzeby
z nagłówków podrozdziałów, które wyświetlają się w tym menu, w
którym domyślnie widzimy „Akapit”. Nie wytłuszczamy nagłówków
dodatkowo. Nie wstawiamy dwukropków czy kropek na końcu;
jeżeli trzeba, korzystamy z
automatycznego wypunktowania lub
numerowania. Nie piszemy tego ręcznie od myślników
itp.;
dodajemy
kategorię (ikonka „hamburgera”, czyli trzy poziome
paski → ikonka metki). Bezpiecznie jest dodać tylko kategorię
gałęzi prawa. Kategorie to nie tagi – jeżeli piszemy o służebności
przesyłu, nie szukamy 7 kategorii: służebność, przesył, prawo
rzeczowe, prawo cywilne, prąd, prawo, ograniczone prawa rzeczowe;
wystarczy samo prawo rzeczowe:
Krok 4: Prośba o sprawdzenie
Prośby o sprawdzenie artykułów
można zgłaszać na Pytaniach
nowicjuszy, na tej samej stronie, na której możemy poprosić o
wyjaśnienie wątpliwości, lub przewodnikom.
Jeżeli podoba Wam się pisanie w
Wikipedii, prosimy o więcej edycji i zapraszamy do do Wikiprojektu
Prawo. Jako aktywni wikipedyści uzyskacie m.in. możliwość
otrzymania wsparcia od Wikigrantów
lub Biblioteki Wikipedia.
Na koniec dwie ciekawostki. Za
pomocą
tego narzędzia możecie dowiedzieć się ile osób czyta Wasz
artykuł i porównywać wyniki innych artykułów. Dodatkowo polecam
obejrzeć filmik o upraszczaniu języka urzędowego. Język prawniczy
jest bardzo podobny do urzędowego, a styl encyklopedyczny ma
cechy języka prostego.
Zdjęcie pustyni autorstwa Murray’a Foubistera dostępne na
licencji CC BY-SA 2.0. Logo
zasad to remiks autorstwa Nohata i Tar Lócesiliona,
dostępny na licencji CC BY-SA 3.0. Ikona „kopiuj-wklej” to remiks
autorstwa Ilmari
Karonena, Rugby471 i Cronholma144 dostępny na
licencji Creative Commons 0. Zrzuty ekranu przedstawiają twórczą
pracę designerów Wikimedia Foundation (w części dotyczącej
oprogramowania) i Tar Lócesiliona (tekst artykułu). Wszystkie te
utwory są dostępne na licencji CC BY-SA 3.0 lub kompatybilnych.
Logo The Wikipedia Library autorstwa Heather Walls dostępne na
licencji CC BY-SA 3.0.
We zamierzchłej historii internetu w 1998 powstał serwis, który
dziś jest DMOZ'em. Wtedy krajobraz sieci WWW wyglądał zupełnie
inaczej niż dzisiaj. Tuzami były na przykład: Yahoo, Netscape i
MSN, wyszukiwarka Google dopiero raczkowała.
Ambitne zadanie DMOZ'u polegało na skatalogowaniu wartościowych
zasobów internetu przez grupę zmotywowanych
redaktorów-ochotników.
Zasady i ideały były w znacznym stopniu pokrewne powstałej kilka
lat później Wikipedii: wspólne działanie ochotniczej,
woluntarystycznej grupy internautów w szczytnym i altruistycznym
celu, dla dobra ogółu.
Katalog tworzony przez miał mieć przewagę nad software'owymi
maszynami
indeksującymi gigantyczne zasoby internetu.
"humans do it
better"
Nie byłem osobiście związany z DMOZ, ale pewnego rodzaju
pokrewieństwo Wikipedii, jakiś sentyment do tego projektu
mam.
Sztuczna inteligencja, deep learning i sieci neuronowe to
zagadnienia, które pojawiły się w cyfrowym "życiu" naszego świata
na szerszą skalę w 2016 roku, a obecnie ta fala zaczyna przypominać
tsunami.
Sztuczna inteligencja wchodzi pod strzechy i do przedsiębiorstw.
Roboty piszą już
sportowe njusy i działają w kancelariach prawniczych.
Wikipedia na swój sposób zdetronizowała Encyklopedia Britannica, choć wydawało się to absolutnie niemożliwe.
Dynamika zmian naszego świata może sprawić, że Wikipedia
przestanie być tym czym jest obecnie. A może zniknie w mrokach
zapomnienia ?
Ponieważ zostałem, po raz kolejny, poproszony o pomoc przy
Wikidanych, zdecydowałem się na stworzenie obrazkowej dokumentacji
dotyczącej tego projektu.
Po tygodniu druga część twórczości Liama pt. Strategia i
kontrowersje, jak on to ujął, „montgomerologii”, pseudonauki
wzorowanej na watykanistyce czy sowietologii (od Montgomery St. w
SF, gdzie
mieści się siedziba WMF). Bohaterką odcinka jest Anne Clin
([[user:Risker]]), która mówi pracownikom WMF, co robią, a co
powinni. Jeżeli nie czytaliście
pierwszej części „montgomerologii”, zróbcie to, zanim
zaczniecie czytać tę tutaj…
Odkąd napisałem pierwszy
tekst z tej serii, podsumowujący kilka równoczesnych
kontrowersyjnych spraw, będący próbą ukazania wspólnego mianownika
tych wątków, nastąpiło trochę zawirowań w siedzibie Wikimedia
Foundation. Najłatwiejsze do zauważenia jest to, że na skutek
nacisków, m.in. petycji społeczności, wypowiedzi kilku byłych
członków Rady Powierniczej i nagłośnienia sprawy w mediach Arnnon
Geshuri zrezygnował z wyznaczonego mu miejsca w Radzie
Powierniczej, co podsumował The Signpost. Ta rezygnacja miała miejsce pomimo
kompletnie bezprecedensowego zachowania pochodzącego z Doliny
Krzemowej Guya Kawasaki, który
zagłosował przeciwko petycji do Rady Powierniczej pomimo
tego, że jest członkiem Rady. To było zresztą jego pierwsze
publiczne wystąpienie odnoszące się do Wikimediów, odkąd został
członkiem Rady –
co opisałem na meta.
Chociaż dobrze przyjęto newsa w sprawie Geshuriego, myślę że ta
sprawa osiągnęła punkt krytyczny dlatego, że była łatwa do
zdefiniowania i wiązała się z zero-jedynkową decyzją: odejść albo
zostać. Większości problemów nie da się tak łatwo rozwiązać. Mam
więc nadzieję, że jako że ta sprawa jest w większości za nami
(została tylko delikatna kwestia zalezienia kogoś na miejsce
Geshuriego [to też za nami – Rada wyznaczyła
Maríę Sefidari, której w 2015 skończyła się kadencja i która w
2015 o mały włos nie została wybrana przez społeczność –
przyp. tłum.]), możemy wrócić do bardziej fundamentalnych problemów
związanych z przywództwem.
Rozumiemy, że dobre 93% z 240 pracowników odpowiedziało na
ankietę. Chociaż wskaźnik poczucia dumy z pracy w WMF i zaufania do
bezpośrednich przełożonych osiągnął 90%, odpowiedzi na cztery inne
pytania mogą sprawić, że uniesiesz brwi:
wyższe kierownictwo przedstawiło wizję, która mnie motywuje: 7%
na „tak”,
wyższe kierownictwo dba, żeby pracownicy byli poinformowani o
tym, co się dzieje: 7% na „tak”,
mam zaufanie do wyższego kierownictwa: 10% na „tak”,
wyższe kierownictwo efektywnie zarządza zasobami (ludzkimi,
finansowymi, wysiłkiem) w kierunku osiągania celów Fundacji: 10% na
„tak”.
The Signpost dowiedział się, że wśród „C-levels” (wyższego
kierownictwa) zaufanie do kierownictwa ma tylko jedna osoba.
Tydzień później szefowa działu kadr Boryana Dineva – osoba
przydzielona do prawdopodobnie najtrudniejszej obecnie pracy w WMF
– podsumowała ankietę na comiesięcznym, publicznie nagrywanym
spotkaniu Monthly Metrics: (41:47)
Zauważyliście kompletny brak jakiegokolwiek napomknięcia o tym,
o czym napisał The Signpost? Nie tylko wy. W części
spotkania poświęconej pytaniom i odpowiedziom Frances Hocutt zadała
pytanie
powtórzone później przez Aarona Halfakera: „dlaczego nie
rozmawiamy otwarcie o najbardziej niepokojących wynikach ankiety”?
(56:01)
Sądzę, że wyjątkowo niskie zaufanie pracowników do wyższej
kadry, łącznie z „C-levelsami”, jest bezpośrednio związane z:
brakiem przejrzystości w określeniu strategii od czasu, gdy
dobiegł końca poprzedni plan strategiczny i gdy miało miejsce kilka
falstartów (np.
ankieta z dwoma pytaniami), co prowadziło do nagłych i
niewyjaśnionych zmian w działach czy opóźnień,
ostatnich oczywistych problemów z przestrzeganiem
organizacyjnych wartości.
W tym przypadku zwłaszcza wartości „niezależności”, „różnorodności”
i „przejrzystości”.
Anne Clin – szerzej znana wikipedystom jako Risker – zgrabnie
połączyła te wątki na początku miesiąca w swoim wystąpieniu na
corocznym spotkaniu pracowników. Wystąpienie zatytułowała „Miejcie
oko na Misję”. Powiedziała:
Obserwatorzy Wikimediów wiedzą od pewnego czasu, że Fundacja
zadecydowała, że search and discovery będzie
strategicznym priorytetem. Nie jest jasne, na podstawie jakiej
decyzji tak się dzieje, ale trzeba to odnieść do Misji i
„globalnego i skutecznego rozpowszechniania informacji”. Nie jest
to coś, co zostało przedstawione na
strategicznych konsultacjach w 2015, nie było dyskutowane w
wezwaniu do działania.
Niedawne ogłoszenie o grancie od Knight Foundation mówi nam, że
zostanie on wykorzystany do badań i stworzenia beta-poprawek
dotyczących wyszukiwania informacji w projektach Wikimedia. Bez
wątpienia Search and Discovery, który już ma wielu
utalentowanych pracowników, pojawi się w okolicy samej góry
proponowanych priorytetów strategicznych, kiedy zostaną w przyszłym
tygodniu przedstawione społeczności, i zostanie mu przydzielony
spory kawałek budżetu 2016–2017. Wyniki z badań finansowanych z
grantu Knight Foundation prawdopodobnie nie ukażą się wystarczająco
szybko, żeby posłużyć się nimi przy projektowaniu budżetu.
To jest jedyne zdjęcie, jakie potrafię znaleźć z tamtego
wystąpienia – Anne przy pulpicie mówi o Radzie [board to po angielsku zarówno rada, jak i
deska – przyp. tłum.]
Jak widać, przewidywania Anne nie sprawdziły się. Z 18 koncepcji
zaproponowanych na konsultacjach tylko jedna zdaje się być
bezpośrednio związana z pracą Search and Discovery:
„Rozpoznanie
sposobów skalowania treści tworzonych, weryfikowanych i
wspomaganych maszynowo”. Jest to dosłownie ostatnia na liście
18 koncepcji (po 6 w „Zasięgu”, „Społecznościach” i „Wiedzy”) i
stonowana słowem „rozpoznanie” (zamiast bardziej określonymi
„zwiększenie” czy „dostarczenie”). W ten sposób ten niby-ukryty
element strategii prowokuje pytanie: skoro to tak mała część
udokumentowanej strategii, dlaczego otrzymuje nieproporcjonalnie
dużo pracowników, finansów, naszej uwagi? Wszystkie projekty
przedstawione na stronie
„Discovery” i w ich planie
trzyletnim są pożądane i mile widziane, ale niewątpliwie zespół
ma nadmiar pracowników przygotowanych do znacznie bardziej
ambitnych wyczynów.
Znów Anne:
To ujęcie Misji zostało ostatnio znowelizowane w listopadzie
2012 – i jest włączone do statutu Wikimedia Foundation. A ta
nowelizacja Misji miała miejsce niedługo po tym, co wielu z nas
pamięta jako decyzję o „zawężaniu
skupienia”. Zwróćcie uwagę na to, co nie zostało włączone w
treść Misji:
ani słowa o Wikimedia Foundation jako organizacji „technicznej i
grantowej”. Podczas gdy duża część budżetu jest poświęcona tym
kwestiom, Rada wciąż uznaje, że pierwszorzędną misją jest
rozpowszechnianie materiałów edukacyjnych, nie technologia czy
granty…
…Engineering – albo, jak teraz się nazywa –
Product, w 2012 miał określone trzy ważne cele: rozwinąć
VisualEditor, rozwinąć opcje mobilne i zrobić duży wyłom w
długotrwałym długu
technicznym. Dwa pierwsze przeszły długą drogę: nie bez
czkawki, ale mamy duży postęp. Było też trochę pracy nad długiem
technicznym – HHVM jest jedynym
znacznym osiągnięciem. Ale rdzeń MediaWiki wciąż zawiera sporo
zbędnego kodu, konające i niekochane rozszerzenia oraz
eksperymenty, które zawiodły donikąd. Nie ma tu większej poprawy;
właściwie widzimy dobudowywanie się długu technicznego, kiedy
powstają nowe rozszerzenia i potem tracą wsparcie, bo ktoś zmienił
zespół albo opuścił organizację. Rozszerzenia i narzędzia
utrzymywane przez wolontariuszy cierpią na enropię, kiedy
wolontariusz decyduje się na pójście swoją drogą i nie ma planu
właściwego zarzucenia jego oprogramowania albo zintegrowania i
wspierania go. Nie ma oczywistego planu wspierania i utrzymywania
infrastruktury, zamiast tego mamy tylko rozmowę o nowych
rozszerzeniach, nowych produktach. Z zewnątrz
wygląda to tak, jakby Fundacja była zajęta robieniem objazdów
zamiast łatania dziur w autostradach.
Jak rozumiem, pierwotnie wniosek do Knight Foundation był
znacznie większy niż otrzymane 250 tys. dolarów.
Jimmy Wales stwierdził, że zastrzeżenia co do szczegółów tego
grantu to „temat
zastępczy”, a zaniepokojenie wykluczonego z Rady Jamesa
Heilmana spowodowane problemami z jawnością jest „kompletną
jebaną bzdurą” (co spowodowało, że James
ogłosił, że niedługo dostarczy dowody na poparcie swoich
twierdzeń). Mam nadzieję, że niedługo zostanie opublikowana umowa
grantowa, co dał znać Jimmy, żebyśmy właściwie wiedzieli, co
zostało obiecane.
Warto zauważyć, że wspomniane wyżej „wezwanie do działania” było
częścią planu
rocznego 2015–2016, ale ocena ryzyka
została opublikowana w tym tygodniu. Prawdopodobnie została
napisana razem z resztą dokumentacji, ale zapomniano ją
opublikować. Tak czy inaczej zawiera ona kilka raczej ironicznych
informacji, kiedy czyta się je post factum:
Ryzyko: niepowodzenie w stworzeniu silnej, spójnej kultury pracy
opartej na wartościach może spowodować odejście wartościowych
pracowników.
Strategie łagodzenia ryzyka:
Ustanowienie inicjatyw, które wspierają nasze zobowiązanie do
różnorodności i stworzenie przestrzeni konstruktywnej,
bezpośredniej i szczerej komunikacji.
Efektywna komunikacja i słuchanie pracowników w sprawie
przyjmowanych wartości i inicjatyw.
Co ważne,
Postanowienie o Celu zawarte w statucie WMF stanowi, że WMF
będzie wykonywała Misję „we współpracy z siecią indywidualnych
wolontariuszy i niezależnych organizacji, w tym Czapterów,
Organizacji Tematycznych, Grup Użytkowników i Partnerów”. Odpowiada
temu ostatnia z Wartości:
„Nasza społeczność jest naszym największym kapitałem”.
Na spotkaniu w ten weekend Rada będzie musiała ustalić, czy
obecne wyższe kierownictwo potrafi dowieść, że dotrzymuje ww.
wartości – w szczególności „koordynacji” i „jawności” w swojej
wizji prezentowanej społeczności i pracownikom – i czy potrafi
zrealizować najnowsze postanowienia strategiczne.
Edit: w ciągu godziny od publikacji tego tekstu i dzień przed
spotkaniem Rady na stronie dyskusji Lili opublikowano „tło
grantu na Silnik Wiedzy”.
Ostatnio przeczytałem
drugi post z serii ‘Strategy and controversy’ autorstwa Liama
Wyatta ([[user:wittylama]]). Z kolei znajomy Liama z
FDC, Michał Buczyński ([[user:Aegis Maelstrom]]), napisał na
fejsie:
Polacy mogliby się bardziej
zainteresować tym jak te projekty w ogóle działają. Pierwsze
pokolenia Wikipedystów z pl wiedziały to z musu, nowym chyba się
wydaje, że to się wszystko dzieje automagicznie.
Pomyślałem, że warto częściej pisać o sprawach międzynarodowych,
o strategii Fundacji (vel strategii ruchu
Wikimedia?). Jeżeli tylko czujemy się wikipedystami czy
wikimedianami, powinniśmy wiedzieć, że to dotyczy każdego z nas.
Może zamiast zmiany skórki usuną nam stronę główną? Pozwalam sobie,
za zgodą Liama, opublikować tłumaczenie pierwszego posta ‘Strategy
and controversy’ z 8 stycznia tego roku…
W przyszłym tygodniu są 15 urodziny
Wikipedii, pierwszy szkic długo oczekiwanego planu strategii
Wikimedia Foundation (WMF)
zostanie udostępniony do konsultacji, a wczoraj zaczęło się
coroczne spotkanie „wszystkich pracowników”. Tymczasem… na górze
toczy się walka o duszę WMF.
Kelly Battles i Arnnon Geshuri
Myleen Hollero, CC BY-SA 3.0
Jak donosi The Signpost, morale pracowników jest rekordowo niskie
(tylko 7% czuje się poinformowanych, tylko 10% ma zaufanie do
kierownictwa),
mamy lukę w jawności, przejawiającą się m.in. w dużej,
planowanej w tajemnicy, reorganizacji działu technicznego [4.
pkt mojego tekstu o 2015 – przyp. tłum.] (zob.
spis na Meta-Wiki),
w zeszłym tygodniu miało miejsce bezprecedensowe
usunięcie Jamesa Heilmana, wybranego przez społeczność na
członka Rady Powierniczej, którego znam osobiście i któremu ufam,
spowodowane utratą „wzajemnego zaufania”. Decyzji
przekonująco bronił Denny Vrandečić, wybrany przez społeczność
członek Rady Powierniczej, którego także znam osobiście i któremu
ufam, ale – według wielu,
w tym według pracownika o najdłuższym stażu, Tima
Starlinga – bez dostatecznego usprawiedliwienia,
w tym tygodniu cios w „zróżnicowanie perspektyw”: dwoje
Amerykanów, mieszkańców zatoki San Francisco, znawców przemysłu
nowych technologii,
zostało wyznaczonych na nowych członków Rady Powierniczej – z
których o jednym (dobranym specjalnie ze względu na doświadczenie w
HR) –
wspomniano w śledztwie Departamentu Sprawiedliwości badającym
sprawę antykonkurencyjnej zmowy płacowej w branży nowych
technologii, co wyczerpująco
podsumował Jim Heaphy.
Przypuszczam, że to nie jest spis niezwiązanych ze sobą
incydentów, a część szerszego problemu: część Rady Powierniczej i
dyrektor wykonawcza Wikimedia Foundation uważają, że WMF
należy traktować jak organizację technologiczną w stylu firmy .com,
bez oglądania się na pracowników i bez wiedzy
społeczności. Ja natomiast zawsze uważałem, że Wikimedia
Foundation jest edukacyjną organizacją non-profit, której
przydarzyło się funkcjonować głównie na polu technologicznym.
Oczywiście rozwijanie oprogramowania jest kluczowe dla naszej pracy
i powinno mieć przydzieloną proporcjonalną część pracowników oraz
budżetu, ale to środki, nie cele.
Całe to tło sprawia, że przyszłotygodniowy [już
jest – przyp. tłum.] szkic strategicznego planu jest bardzo
ważnym dokumentem. Jego odpowiednikowi na lata 2010–2015
towarzyszył wielki projekt
konsultacyjny, tym razem była tylko
ankieta na dwa pytania. Jak mi powiedział Philippe Beaudette
(za zgodą na publikację), Community Facilitator pierwotnego procesu
ustalania strategii, a później Director of Community Advocacy
(który także ostatnio opuścił WMF),
Wikimedia Foundation ma jeden jedyny strategiczny kapitał:
społeczność edytujących. Inne organizacje mają wielkie zaplecze
techniczne, tony pieniędzy, dobre oprogramowanie, bystrych
pracowników… ale żadna nie ma społeczności. Szczerze mówiąc, smutno
mi, że ten jeden jedyny strategiczny kapitał nie jest już w centrum
wyznaczania strategii.
W listopadowej prezentacji znalazła się zapowiedź wyznaczania
strategii, w której przedstawiono trzy priorytety (slajdy 28–30):
1. „bardziej globalne zaangażowanie ludzi (zasięg)”, 2. „dopasowana
pomoc społecznościom (społeczność)”, 3. „szerszy zakres treści
(wiedza)” i opisano potrzebę „określenia priorytetów zasadniczej
pracy” (slajdy 32–33). Wszystko to chwalebne cele, ale tylko
przykładowe („budowa objętości”, „wzrost zaufania”, „rozwój
narzędzi”).
Mimo wszystko podejrzewam, że główny strategiczny kierunek
został już po cichu określony. W skrócie, wygląda na to, że będzie
próba stworzenia internetowej Następnej Wielkiej
Rzeczy kosztem rozwijania tej wielkiej rzeczy, którą
już mamy.
Jak w maju zauważyła
Risker, „wydaje się, że Search and Discovery, nowy zespół, ma
wyjątkowo dobrych pracowników z nieproporcjonalną liczbą
informatyków, podczas gdy, jak się wydaje, w pozostałych obszarach
informatyków brakuje”,
czerwcowa prezentacja pracowników „Zapowiedź strategii”
traktuje o stworzeniu „silnika wiedzy, w który użytkownicy,
instytucje i komputery z całego świata wnoszą wkład i odkrywają
wiedzę”. FAQ nad-zespołu Discovery
opisuje ten projekt jako „poprawę obecnej infrastruktury
CirrusSearch wielojęzyczną, wieloprojektową wyszukiwarką zwracającą
odpowiedzi bardziej związane z zadanym pytaniem oraz włączanie
nowych źródeł danych do naszych projektów”,
jak wspomniałem wyżej, mamy dwie osoby z Doliny Krzemowej
wyznaczone do Rady Powierniczej. Dołączą do grona,
w którym z Doliny Krzemowej jest już inwestor venture capital Guy
Kawasaki oraz sam Jimmy Wales, przedsiębiorca internetowy. Nie ma
nikogo wyznaczonego ze względu na jego zawodowe doświadczenie w
edukacji, sektorze non-profit, społecznościach czy krajach
rozwijających się.
Zgadzam się z ogólnym założeniem, że wikimediową wyszukiwarkę
można poprawić, ale nie znam nikogo, kto uważa, że „zindeksowany
i strukturalizowany zasób Zjednoczonych Źródeł Otwartych
Danych” powinien być tym jedynym strategicznym
priorytetem. Rozpoczynanie czegoś zupełnie nowego jak Zjednoczona
Wyszukiwarka jest ciężkie i próba włączenia
zewnętrznych źródeł (tamten link sugeruje włączenie
US Census i DPLA) jest jeszcze
cięższe, szczególnie że technicznych potrzeb jest tak wiele.
Cytując Philippe’a raz jeszcze, „na przykład naprawa relacji między
językami i projektami, albo budowa zestawu narzędzi dla
administratorów na urządzenia mobilne, albo spłacanie naszego
technicznego długu, albo wprowadzenie opieki/zarządu/kontroli nad
najważniejszymi narzędziami w celu zapewnienia ich stabilnego
rozwoju…” itd.
Funds Dissemination Committee (w którym zasiadam jako członek
wybrany przez społeczność)
oświadczył w listopadzie, że jest „przerażony sposobem, w jaki
WMF przedsięwzięła roczny i strategiczny plan oraz podejściem WMF
do jawności finansowania (albo jej brakiem)”. W odpowiedzi
WMF rozważa przedstawienie planu rocznego 2016–2017, opartego
na ww. planie strategicznym, w procesie spełniającym pod względem
jawności i szczegółowości standardy wymagane od uczestników
programu Annual Plan Grant [program finansowania stowarzyszeń typu
Wikimedia Polska przez WMF – akurat my {jeszcze} w tym nie
uczestniczymy, ponieważ {póki co} wystarczają środki z OPP – przyp.
tłum.].
W następnych tygodniach okaże się, do jakiego stopnia zmiana
podejścia ludzi z Doliny Krzemowej – czy to na podobieństwo
podejścia pracowników i społeczności, czy nie – jest prawdziwa. Jak
ówczesny przewodniczący Rady Powierniczej
Jan-Bart de Vreede powiedział, przedstawiając Lilę Tretikov
jako nową dyrektor wykonawczą,
Jesteśmy unikatowi pod wieloma względami, ale nie na tyle, żeby
zignorować podstawowe trendy i ogólnoświatowe zmiany w korzystaniu
z internetu i wyszukiwaniu wiedzy… mam nadzieję, że wszyscy
będziecie częścią tego następnego kroku w naszej ewolucji. Ale
rozumiem, że jeżeli zdecydujecie się na odwik, to być może będzie
to tym, co ma być.
Liczę na komentarze. Gdziekolwiek, byle wyszło na to, że inni
polscy wikipedyści wiedzą więcej niż wcześniej. Może ktoś się
zaangażuje. Nie ukrywam, że bliżej mi do podejścia technologicznego
niż edukacyjnego, z wielkim jawność: więcej;
!important.
Tłumacząc tekst przekonałem się, że bariera językowa jest
ogromna. Lingua franca Wikimediów jest angielski, w zw. z
czym Australijczyk zapodaje losowe cytaty skąd chce i ile chce, a
Polak musi tłumaczyć wszystko: od dokumentacji, przez oficjalne
wypowiedzi WMF odwołujące się do dokumentacji, do komentarzy do
tych wypowiedzi, i oczywiście komentarzy komentarzy. W efekcie w
meta-społeczności jest nadreprezentacja English natives,
Holendrów itp., a Polacy żyją na na marginesie obiegu informacji.
Uff, behold interesting times we live in.
Organizacja wspaniała, fotki ładne, trunek smakował,
współlokator na medal, nocne rozmowy udane. Sukces odtrąbiony,
formuła się sprawdziła, chcemy jeszcze. Wśród zlotowiczów było
jednak kilka osób, które inaczej mierzą sukces. Między innymi ja,
bo interesuje mnie program
i zmiany wywołane tym, co się działo. Jeszcze bardziej interesuje
mnie to, że zmian nie ma, chociaż wiemy, jakie powinny być…
1. Co nam przyniósł Zlot
Polimerek mówił ciekawie o anatomii i fizjologii (cenne
spostrzeżenia!), ale część druga, dyskusja, rozmyła się i chyba
roztrwoniliśmy Polimerkowe zagajenie. Następnie ukłony dla Encego
za pomoc w tłumaczeniu VE/instrukcji,
bez niego bym sobie nie poradził. Później przez kilka godzin
dopracowywałem tłumaczenie do plwiki, więc wyłączyłem się z
programu. Błyskawiczne prezentacje przyniosły likwidację „próżnych
wyrażeń” i
poprawkę w streszczeniu WP:WER. To mi się podoba!
Następnego dnia rano mocne uderzenie na mózgi członków
Stowarzyszenia: 50 kompozytorów, fach Alenutki,
crowdfunding, fundraising, pracownik od
fundraisingu, budżet WMPL. State of Wiki Loves… i
rezygnacja z WLZ
2016. Na końcu warsztat warsztatów. Ale wcześniej
najważniejsze:
2. „Warsztat: Komunikacja z nowicjuszami” by Magalia
Jeżeli nie wprowadzimy pomysłu Wierylee (48h na dopracowanie
nowego artykułu przed likwidacją/przeniesieniem do brudnopisu –
nawet takiego bez źródeł), jeżeli nie zrozumiemy, że brak
wyrozumiałości, pisanie na szybko i na chłodno do nowych to też
gryzienie, jeżeli nie poluzujemy obrony ozetów, nie zainwestujemy w
5. filar (moim zdaniem zapomniany) to będzie źle i cały
zlot do kosza. Już nie jest dobrze, bo nic, o czym wspomniałem
w tym akapicie, jak dotąd nie zostało przedstawione w
Kawiarence.
Halibutt i Magalia dowiedli, że gryzienie jest problemem.
Uczestnicy zlotu potrafili wymienić tylko jeden nick ponoć
gryzącego wikipedysty, jakby gryzienie nie było problemem całej
społeczności i jakby ktoś „gryzł bardziej”. A przecież to, że ktoś
ponoć gryzie, wiemy tylko z relacji prowadzących warsztaty –
to nie jest nasza własna myśl. Kiedy powiedziałem „znajdźcie drugi
nick, trzeci”, zlotowicze wyglądali na zaskoczonych. Pojawił się
pomysł „za gryzienie do KA”.
KA nie przyjmie skargi na gryzącego, choćby dlatego, że:
nikt kontaktujący się z nowymi nie jest – pardonez-moi
mon français – chamem. Dzisiejsze
„gryzienie” to standardowe komunikaty i wydaje się, że jeżeli ktoś
odstaje od reszty, to pozytywnie, tzn. wielu z nas musi się
poprawić, a nie niewielu z nas można by odesłać do KA. Wniosek:
testy, komy i inne muszą być zintegrowane i przeredagowane, muszą
też wymuszać na wstawiającym dodanie kilku słów (nie skrótów) od
siebie,
„prosimy
nie gryźć nowicjuszy”, zredagowane jak esej, nie jest zasadą,
czymś „normatywnym”, nie zawiera przykładów, nie jest jasne i
łamanie tego „prosimy” nie jest podstawą działania KA (zob.
polityka arbitrażu). Pierwszy punkt polityki mówi o konflikcie
personalnym, a czwarty o łamaniu zasad pisania artykułów, w związku
z czym piąty filar (IAR)
i wszystkie pochodne to „bezzębne” wytyczne. Wniosek: trzeba
wprowadzić kategorię odpowiadającą angielskiemu
behavioral guidelines, a „nie gryź nowicjuszy” uczynić
zobowiązaniem do bycia wyrozumiałym, wraz z zanonimizowanymi
przykładami z edycji na plwiki.
3. Polska szkoła edytowania. Źródło gryzienia
Fabrice Florin (WMF) promował culture
of kindness. „Bądźmy bardziej mili”. Moim zdaniem Fabrice
próbował zmniejszać objawy, ale nie dotarł do przyczyn. Gryzienie
nie jest brakiem bycia miłym. Jest ono w większości nieświadome i
wynika z przyzwyczajenia do formalizmu. Być może pewną rolę odgrywa
wychowanie w
systemie prawa kontynentalnego. Trzeba mieć dużo serca i luźny
stosunek do zasad, żeby nie gryźć. Wiem co piszę, sam czasami gryzę
Halibutta.
Dużym osiągnięciem był odwrót od głosowań na rzecz dyskusji.
Jednak równocześnie sformalizowaliśmy sposób pisania artykułów,
traktując zalecenia i usus tak samo jak zasady, czyli „rób
tak i nie inaczej”, zamiast „jeśli nie wiesz jak postępować,
postępuj tak”. Trzeba zaktualizować, posprzątać teksty zasad i
zaleceń (co już trwa: NPOV, WER, zob. MoS),
wyjaśnić podział na zasady i zalecenia, rozbić je na podkategorie
(w tym: dot. edytowania artykułów, dot. zachowania), wzmocnić IAR,
ŚMS i poluzować sposób interpretacji. Wtedy nie będzie podstaw
do tłoczenia nowicjuszom jedynie słusznego sposobu edytowania.
Masti powiedział mi na zlocie: „szanuję to, co robisz, ale
rozbiłbym ścianę, o którą się opierasz”. Jeśli chodzi o edytowanie
artykułów, popieram mastiego.
Ruch Wikimedia to niemal synonim społeczności użytkowników,
dlatego programiści muszą szanować przyzwyczajenia. Z kolei
programistów jest niewielu, jak na tak popularną witrynę jak
Wikipedia. To sprawia, że zmiany idą małymi krokami i nawet
najważniejsze z nich bywają obarczone wadami, których nie sposób
szybko rozwiązać. Opiszę kilka – moim zdaniem największych – zmian
po technicznej stronie Wikimediów. Pomijam mnóstwo drobnych
usprawnień. Zainteresowanych szczegółami odsyłam do archiwów Tech
News i na mojego
bloga, gdzie znajdziecie „wersję rozszerzoną” niniejszej
notki.
Flow
Oprogramowanie stron dyskusji. Nie wygląda jak strona MediaWiki,
tylko składa się z wątków i postów, jakie znamy chociażby z
Facebooka, serwisu, na którym dyskusje wikipedystów są chyba
bardziej wartkie niż w Wikipedii. Ja osobiście jeśli mam
dyskutować, wolę komentować pod postem, niż uprawiać typową dla
Wikipedii epistolografię. Niestety, brakuje kilku ważnych funkcji
(takich jak przenoszenie postów między wątkami), niektóre gadżety
dostępne w naszej Wikipedii blokują działanie Flow, a nade wszystko
został on chłodno przyjęty przez dużą część społeczności. Trafił
więc do zamrażarki, w międzyczasie jego twórcy zajęli się rozbudową
powiadomień. Na początku 2016 roku rozbudowane powiadomienia trafią
do użytkowników. W 2016 można się spodziewać uzupełnienia
niektórych braków.
Kamień milowy, magia ukazująca chyba najlepiej, że Wikimedia są
jedyne w swoim rodzaju. Dopiero w 2015 roku zdołano zagwarantować,
że konto użytkownika jest jedno na wszystkich (niemal 900) wiki
projektów Wikimedia. Nikt nie może sobie wybrać naszej nazwy
użytkownika, wszędzie mamy ten sam nick, to samo hasło i bez
odrębnej rejestracji możemy edytować jakuckie Wikiźródła czy
afrykanerskie Wikibooks. Wszędzie mamy tę samą tożsamość. Pojawiło
się zielone światło do zbudowania wielu bardzo użytecznych
narzędzi. Są to między innymi:
Jednolita strona użytkownika – jeżeli nie
utworzyłem strony użytkownika na wspomnianych jakuckich
Wikiźródłach, nie jestem dla jakuckich wikiskrybów Panem Nikt,
ponieważ widzą moją stronę użytkownika w takiej postaci, jaką
edytowałem na Meta-Wiki. Jest pomysł, żeby coś o podobnej funkcji
zrobić dla stron dyskusji (chyba będzie to inaczej działało).
Rozbudowane powiadomienia – projekt, którym
zajmują się obecnie twórcy Flow. Edytując jedną wiki – powiedzmy
anglojęzyczną Wikipedię – zobaczymy, że na innej wiki – powiedzmy
polskojęzycznym Wikisłowniku – ktoś nam podziękował, albo nas
zawołał, albo napisał na naszej stronie dyskusji, albo… Prace nad
tym projektem trwały dość długo i jestem bardzo ciekaw, jak
przyjmie go polskojęzyczna społeczność.
Od tego roku edytor wizualny o wiele lepiej niż edytor kodu
źródłowego radzi sobie z wstawianiem przypisów do stron
internetowych i publikacji mających DOI, z tabelami oraz wzorami
matematycznymi. Mamy możliwość przeskakiwania między edytorami
dowolną liczbę razy bez utraty zmian, co weszło mi w krew chyba
lepiej niż sprzątanie kodu… Możemy też ładować pliki na Commons,
nie wychodząc z okienka edycji artykułu. Obecnie około połowa
użytkowników niezalogowanych edytuje za pomocą edytora wizualnego,
co daje 14% wszystkich edycji autorstwa nie-botów. Ten odsetek
plasuje nas w wikimediowej normie.
Zastanawiam się, jakim hamulcem jest niechęć doświadczonych
użytkowników wyrobiona w lipcu 2013 – bo na pewno jakimś jest.
Wiem, że niektórzy chcieliby, żeby edytor wizualny obsługiwał takie
skrypty jak WP:SK. To nie ma sensu, on nie edytuje kodu, zwróćcie
uwagę, że Microsoft Word też tego nie robi. Łatwiej użyć skryptu w
edytorze wikikodu i przełączyć się na wizualny – sam tak
robię.
Przegrupowanie Engineering, Community Tech i Wishlist
Survey
W kwietniu 2015 przegrupowano dział techniczny Wikimedia
Foundation (WMF). Struktura podzielona według zadań (wyznaczonych
wewnętrznie) została zmieniona na podzieloną według potrzeb
(zewnętrznych). Jeden zespół zajmuje się potrzebami czytelników,
inny – edytorów, jeszcze inny – zaawansowanych wikipedystów. Co
prawda WMF musi popracować nad przejrzystością procesu decyzyjnego,
ale przynajmniej wiadomo, kto za co powinien być
odpowiedzialny. Dla społeczności najbardziej interesująca jest
chyba ankieta – lista życzeń, w której wybrano dziesięć
najważniejszych zadań dla zespołu pracującego dla zaawansowanych
wikipedystów.
Narzędzie ułatwiające tłumaczenie artykułów. W niektórych
językach działa świetnie: dzięki niemu powstały dziesiątki tysięcy
artykułów i tylko pojedyncze trafiły do kosza. Niestety Content
Translation nie daje rady przy przypisach bibliograficznych i
językach fleksyjnych, co bardzo przeszkadza polskojęzycznym
wikipedystom. Dodatkowym problemem jest brak dobrego
autotranslatora (czekamy na podłączenie autotranslatora sprawnie
tłumaczącego na polski z rosyjskiego). Ten produkt wymaga jeszcze
wielu usprawnień i jego autorzy mają tę świadomość. Mają także
świadomość, że brakuje im etatów.
Skoro pomijamy drobne uprawnienia, polscy wolontariusze wypadają
blado w porównaniu z amerykańską korporacją. Na początku roku
podsumowaliśmy badanie stron pomocy, dzięki któremu wiemy, jak
zabrać się za poprawę ich funkcjonalności. W połowie roku pojawił
się pomysł przetłumaczenia Manual of Style obecnego w
anglojęzycznej Wikipedii. W 2016 roku ten temat będzie
kontynuowany. Serdecznie zachęcam do pomocy w pisaniu przewodnika
redakcyjnego (kontakt).
Mowa o Ankiecie-liście życzeń społeczności 2015, która trwa do
14 grudnia. Najpierw w przypadkowej kolejności wymienię propozycje,
na które możemy głosować (zachęcam), potem notka podsumowująca +
informacja o szerszym kontekście (kto, po co, kiedy)…
Od razu widzę zagrożenia, po pierwsze szablonów służących temu
samemu będzie więcej niż mrówków, po drugie dokumentacja szablonów
będzie najczęściej tylko po angielsku, po trzecie nieudane będą ew.
wszystkie poważniejsze próby standaryzacji (w dowolnym celu: czy to
dla ułatwienia niezorientowanym, czy dla odrestaurowania
designu).
Ale szansa jest większa niż zagrożenia: nie trzeba będzie
kopiować kodu, pilnować aktualizacji (kompatybilności)
rozproszonych wersji, może uda się zbudować międzynarodową
społeczność pilnujących szablony (oby to nie wyszło
tak) i, mając doświadczenia Commons, powziąć na starcie
postanowienia co do minimalnych standardów, np.
metadanych. Do tego dojdzie dostępność fajnych gadżetów, które
obecnie są tylko na enwiki wyłącznie dlatego, że nikomu nie chce
się ich popularyzować (por. koszty
transakcyjne).
Jedną z największych zmór są martwe linki zewnętrzne (ob.
133 tys. na plwiki). Najlepiej byłoby, żeby każdy link
zewnętrzny dostawał prędzej czy później swój zarchiwizowany
odpowiednik podany na wiki, ale obrobienie wszystkiego przez
wolontariuszy czy ich boty jest niewykonalne. Chyba nie ma
szczegółowego pomysłu, jak to zrobić, ale kierunek jest słuszny,
towarzysze, i ja go wspieram.
Wiadomo, że nawet stałe IP nie jest do końca stałe, co niby
przesądza o tym, że lepiej nie nawiązywać relacji z anonimami. Ale
nawet jeśli
podziękowanie może trafić w nie te ręce co trzeba, to i tak
czasem brakuje możliwości wysłania pozytywnej reakcji za dobrą
edycję. Teraz przecież dla anonimowych mamy tylko narzędzia do
zadawania bólu (anuluj, cofnij, blokada) i jakoś nie rezygnujemy z
blokad tylko dlatego, że czasami biją po łapkach nie tych co trzeba
(jak np. wtedy, kiedy tłumnie byliśmy w zablokowanym hotelu).
Skoro jest globalna strona użytkownika, to mogłaby i być
globalna strona dyskusji. To super funkcja dla osób działających na
>1 wiki. Myślę, że będzie to działała inaczej niż globalna
strona użytkownika. Ta funkcjonuje w ten sposób, że nasza strona
użytkownika na Meta-Wiki wyświetla się na azerskich
Wikiźródłach, jeśli tam nie ma analogicznej strony.
Czujemy już, o co chodzi? Globalna strona użytkownika działa tam,
gdzie lokalnej strony nie ma i jest to stabilne, bo tylko
ja mogę tworzyć swoją stronę użytkownika. Natomiast strona
dyskusji jest po to, żeby ją inni tworzyli, czyli azerski
wikiskryba ma móc edytować jakby gdzie indziej (az.wikisource), a
my mamy móc widzieć jakby gdzie indziej (pl.wikipedia). To troszkę
atrapa Flow, bo Flow jest na
zewnątrz wobec wszystkich wiki i to on jest prawdziwie globalną
stroną dyskusji.
Co tu dodatkowo opisywać: obserwowanie użytkownika
(świetne do obserwowania nowicjuszy, trolli,
współpracowników), obserwowane cross-wiki (piszę polskojęzyczną
Wikipedię i Wikisłownik, na jednym widzę Obserwowane z obydwu).
Globalizacja!
Jak widać, jestem fanem cross-wiki/globalizacji/centralizacji.
Po pierwsze w życiu niektórych wikipedystów przychodzi moment,
kiedy aktywizują się na innych projektach i oddzielenie serwisów
wiki zaczyna im coraz bardziej przeszkadzać. Po drugie niektóre
rzeczy w Wikimediach zaczynają ze sobą współgrać między wiki, a
niektóre są całkiem scentralizowane (choćby konto
użytkownika).
Kto, po co, kiedy
Żeby wiedzieć, czym jest Ankieta-lista życzeń społeczności 2015
(2015 Community Wishlist Survey), należy znać szerszy kontekst,
czyli zespół, który ją rozkręcił, i proces decyzyjny, którego
etapem jest Ankieta.
Bodajże
w kwietniu 2015 dział Engineering Wikimedia Foundation (WMF) został
zreorganizowany tak, żeby poszczególne zespoły zajmowały się
grupami „interesariuszy”, „uczestników” czy też personae.
Wyodrębniono np. czytelników (zespół Reading), edytorów (Editing)
i, co ważne, doświadczonych wikipedystów (Community
Tech). Jak w lecie powiedział Matma Rex (Software Engineer,
WMF), nikt nie wie, czym będzie się zajmował Community Tech i każdy
sobie wyobraża, że tym, co wyobrażającemu jest potrzebne. Wiadomo
było tylko
tyle.
Wreszcie zespół ogłosił, że społeczność sama zadecyduje.
Mieliśmy miesiąc na nadsyłanie propozycji tego, czym Community Tech
ma się zająć, a potem dwa tygodnie na głosowanie na 10
najfajniejszych propozycji. W głosowaniu może wziąć udział każdy,
kto wykonał 100 edycji, nie ma ograniczenia liczby propozycji,
które można poprzeć/skrytykować. Prawo do komentowania ma
absolutnie każdy. Następnie zespół przeprowadzi ewaluację 10
najpopularniejszych propozycji i weźmie się do roboty. A będzie
tego trochę. Powyżej zamieściłem infografikę ilustrującą ten
proces, szczegóły są
tutaj.
Wiecie jak wygląda nieświadomy
komplement dla Wikipedysty?
Tak
Przyznaję, że w ciągu
ostatniego tygodnia przysiadłem trochę do Zdezaktualizowanych.
Siedziałem. Oznaczałem oraz rewertowałem. Zrobiłem w ciągu tygodnia
ponad 2000 oznaczeń. Stan Zdezaktualizowanych spadł z tradycyjnych
około 4000 tysięcy do około 2000. Lag z 40 dni spadł do 25
dni.
Efekt – zwykle w ogłoszeniach
wiszące ogłoszenie z gatunku „Przyjdź, pomóż, ojczyzna
czeka” o zdezaktualizowanych zostało zamienione przez coś
innego.
Fajnie widzieć efekt ciężkiej
pracy przez tydzień.
Jednocześnie mam świadomość, że taka
osoba-spychacz jest potrzebna stale żeby nie było takich kolejek.
Kiedyś taką osobą był Maikking. Później Elfhelm. Później PG. Teraz
takiej osoby brak. Dlatego trochę pomogłem.
Ale przyznaję ze przeglądać te edycje to
często jest koszmar wikipedysty. Ci wrestlerzy z wszelkimi błędami
jakie można wynieść z wyuzdanej fantazji polonisty. Ci hip-hopowcy,
którzy mają same przekleństwa. Te miasta, w których ludzie dodają
link do forum osiedla na którym są 4 posty.
Ciężko jest być dobrym wikipedytą na
Zdezaktualizowanych.
Można się spodziewać, że tak jak Wikipedia jest codziennie
potrzebna każdej osobie potrzebującej zdobyć szybką wiedzę na
określony temat, tak Wikipodróże staną się ważnym źródłem
informacji turystycznych.
– tak 15 lutego 2013
na blogu Stowarzyszenia o nowym projekcie siostrzanym pisali
Alan ffm, Kpjas i Marek Mazurkiewicz. Plany były ambitne; Kpjas
stwierdził, że Wikipodróże są w stanie powtórzyć sukces Wikipedii.
Na początku serwis miał kilkunastu aktywnych użytkowników i ok. 2
tysiące stron zaimportowanych z Wikitravel. Trzeba było poprawić te
strony, a także stworzyć mechanizmy, które każda wiki mieć powinna.
Wybrano kilku tymczasowych adminów, w tym gronie znalazłem się i
ja…
Od początku moim zadaniem było dbanie o porządek w
przestrzeniach meta, o przyrost formy nie większy od przyrostu
treści. Przykładowo usunąłem strony związane z biurokratami, skoro
biurokraci funkcjonują tylko na dużych, starszych wiki. Podobnie,
dopóki społeczność liczy kilka – kilkanaście osób, sztywny
regulamin przyznawania uprawnień, kopia z Wikipedii, w nowej wiki
byłby biurokratyczny. Pomimo licznych propozycji do dziś żadnego
nie ustaliliśmy i dobrze.
Stagnacja przyszła szybko: zapał kilkunastu osób wyczerpał się
zaraz po starcie, nowi ich nie zastąpili. Rozwijanie zalążków
okazało się nieatrakcyjne, chęć rozwijania „dodatków” (stron meta
czy szablonów obsługujących bardziej meta niż main) była większa. W
kwietniu 2015 Drozdp i Kpjas zrezygnowali z miotły admina,
Ślimaczek dostał nówkę (na pół roku), ja swoją utrzymałem (na pół
roku) i tylko Alan ffm utrzymał swoją na stałe. Teraz Wikipodróże
mają jednego administratora i moim zdaniem lepsze to niż duże grono
nieaktywnych Niegdyś Zasłużonych.
Nie ma strategii przyciągnięcia nowych użytkowników. 1,5 roku od
uruchomienia Wikipodróży ukazał się
wpis na blogu o 3 tysiącach haseł (pamiętamy, ok. 2 tysiące
były już na starcie), wygłoszono 2–3 prezentacje na konferencjach
Wikimedia Polska i jeśli chodzi o wsparcie organizacyjne, to byłoby
na tyle.
Kolejny projekt siostrzany leży i się nie rusza. Czy przywrócimy
mu dobrą kondycję? Czy powinniśmy się starać? Na pewno zewnętrzne
wsparcie Stowarzyszenia skierowane na robienie edycji (np.
wikigranty) powinno być najwyżej dodatkiem do edycji zrobionych
niezależnie od Stowarzyszenia, tak jak to ma miejsce w Wikipedii i
Commons. Inaczej wyszłoby coś, co nazywam „przetaczaniem krwi
martwemu”. To brutalne, wiem, ale tak każe ostrożność wydawania 1%
OPP i zasada wolontariackiego, oddolnego rozwoju Wikimediów. Tylko
jak sprawić, żeby pacjent sam zaczął oddychać, wstał i poprosił o
suplement diety?
Ten post został napisany parę lat
temu i pozostał w wersji roboczej, a teraz go dopiero
odgrzebałem.
David
Shankbone
Prawdopodobnie niewielu w Polsce o nim słyszało. Nawet w gronie
polskich Wikipedystów. A jest to postać nietuzinkowa, która wiele
zrobiła dla Wikipedii (Wikimediów) i jest znana daleko
poza jej kręgami.
David Shankbone. Bo to o nim mowa, jest pisarzem i
fotografem z Nowego Jorku. Już wiele lat temu zwróciłem na niego
uwagę ponieważ jego determinacja i siła przebicia pozwoliła mu
wykonać dla Wikipedii/Wikimediów zdjęcia bardzo znanych osób z
życia publicznego i polityki. Wartość takich zdjęć opublikow anych
na licencji CC, w tamtym czasie była, nie do
przecenienia przy problemach licencyjnych ze zdjęciami dostępnymi w
internecie.
Tysiące zdjęć w wysokiej rozdzielczości Davida Shankbone'a
ilustruje hasła w Wikipedii i projektach siostrzanych. Jego
kreatywna działanie pozwoliło zilustrować wolną treść wolnymi
ilustracjami.
Nie tylko z działalności fotograficznej jest znany David Shankbone.
Na Wikinews, siostrzanym projekcie Wikipedii, którego domeną jest
dziennikarstwo obywatelskie, David przeprowadził ponad 40 wywiadów
ze znanymi postaciami ze świata show-businessu i polityki.
Z niewiadomych mi powodów David Shankbone zniknął z Wikipedii i
Wikimedia Commons w połowie 2014 roku.
Jak poniżej widać popularność tego bloga nie zabija
The WordPress.com stats helper monkeys prepared a 2013 annual
report for this blog.
Here’s an excerpt:
A San Francisco cable car holds 60 people. This blog was viewed
about 950 times in 2013. If it were a cable car,
it would take about 16 trips to carry that many people.
Na angielskiej Wikipedii swego czasu powstała incjatywa
współpracy z renomowaną instytucją, która jest bazą danych z
zakresu nauk medycznych (szerzej biologicznych) a nazywa się
The
Cochrane Library.
W ramach tej akcji the
Cochrane Library zgodziła się,
przydzielić 100 Wikipedystom darmowe konta z dostępem do baz danych
zgromadzonych w tej bibliotece.
Zgłosiło się ponad 60 osób z różnych wersji językowych Wikipedii i
wszyscy uzyskali dostęp (o ile wiem).
Między innymi osobą, która uzyskała ten przywilej jestem ja.
Wikipedyści, którzy chcieliby uzyskać pomoc w uźródłowieniu haseł
(lub inne informacje z tej bazy) proszeni są o kontakt przez moją
stronę lub w sprawach pilnych e-mailem.
Za jakiś czas chcę opublikować update z moich doświadczeń z tą bazą
danych.
Od pewnego momentu stać mnie jedynie na krótkie linki na
profilu
bloga na Facebooku. Uważam mimo wszystko, że jak na polskie blogi o
Wikipedii to tam dzieje się najwięcej. Może nie najbardziej
sensownie – ale jakoś idzie. A ostatnio dodawałem tam linki do
takich rzeczy:
tumblra z takimi kategoriami jak category:Rear views of
pigeons, albo Category:Children sitting on other people’s shoulders
[link]
Grę dla wikipedystów pod tytułem połącz hasła na en.wiki za
pomocą szesciu linków [link]
Tak więc jeżeli interesuje cię dostawanie takich linków i masz
konto na Facebooku to „polub” stronę bloga. (co do G+ to jedynie
jak ktoś poprosi to zrobię profil).
Yarl uświadomił mi jedną sprawę związaną z nowym systemem
powiadomień, więc pozwólcie że się z wami nią podzielę.
Nowy system powiadomień będzie miał (przynajmniej na początku)
bardzo wielu wrogów. Będą oni krytykowali każdą z opcji po kolei.
Jedną z najbardziej krytykowanych będzie „Wzmianka” czyli gdy ktoś
o tobie napisze na stronie dyskusji. Bo to takie facebookowe i tak
bardzo nas upodabniające do FB, co podobno jest tak przerażające i
upadlające.
Dotychczas podczas dyskusji dwóch wikipedystów każdy z nich
pisał na stronie dyskusji drugiego. Przez co żeby zrozumieć o co
chodziło w wątku trzeba było skakać pomiędzy stronami. Stosowano to
dlatego że po wpisie na stronie dyskusji ten dostawał powiadomienie
„pomarańczowym paskiem”. A gdy ktoś odpowiedział tam gdzie dyskusja
się toczyła to nie dostawał, a ciężko było dodawać wszystkie strony
dyskusji do obserwowanych. Ech gdyby był jakiś sposób na połączenie
tego w jedną dyskusje, którą dałoby się po ludzku czytać.
No to teraz jest. Po prostu podczas pisania odpowiedzi zacznij
od [[USER:Nick osoby z którą rozmawiasz]] i ona dostanie
powiadomienie że coś napisałeś. Proste, jasne i dla każdego kto
będzie miał włączone to powiadomienie będzie działało.
A jeżeli ktoś uzna takie powiadomienia za
„pseudospołecznościowe” i je wyłączy? Cóż – będzie dalej rozmawiał
w kilku miejscach podczas dyskusji z kilkoma ludźmi. Bo przecież
nie jesteśmy FB i nie musimy być rozsądni.
Wikipedyści zapominają że krytykując FB krytykują miejsce
stworzone do tego żeby rozmawiać. Jeżeli spojrzycie na komentarze
na FB to są one znacznie lepszym miejscem na prowadzenie dyskusji
niż strony dyskusji Wikipedii. Więc skoro krytykujemy FB,
krytykujemy lepsze miejsce do dyskusji dwóch wikipedystów.
Bardzo mnie ciekawi kiedy i czy zmieni się styl odpowiadania
wikipedystów z obecnego „na stronie drugiego wikipedysty” na
en,wikowy „na mojej stronie wikipedysty”. To będzie jasny sygnał
jak bardzo zmiany techniczne wpływają na zwyczaje ludzi.
As author of Wikistats I always took a keen interest in how
wikimedians judged about or participated in the friendly rivalry
between language versions of our projects. After all I helped to
make the ranking between versions more visible. Too often to my
taste I witnessed on-wiki conversations that some language project
had been surpassed in number of articles by another, and even a few
times that “a bot will fix this”. So I became a little wary about
mass article creations by bots, and the true motive of their
makers. When several bots on the Dutch Wikipedia started to ‘flood’
the wiki with taxonomy stubs [1] I was really disappointed. What
good would that do? Who is going to extend these articles, or even
just visit them, other than via ‘Random Article’?
A few months ago I helped an acquaintance to upload images
to Commons. Already for many decades she has a passion for one
particular subclass of slime moulds (‘myxomycetes’) and she has
shot many wonderful pictures, some of which also are stored in the
archives of Leiden University (Herbarium). A small selection of
these pictures now also have found a safe haven on Commons: [2]. We
spent several sessions to master the intricacies of Windows, and
the browser, and pitfalls on Commons (for a computer novice even
Upload Wizard can be daunting). As she is of very respectable age,
I admire her persistence. It would have been nice if we could have
finished by adding some of these pictures to the proper article
about this very species. And then I discovered these did not yet
exist in many or all occasions, and I regretted it. Even a stub
with just a taxonomy info-box would have been a great placeholder.
Although she could create some of those articles herself
knowledge-wise, I don’t see her master wiki syntax yet, and also
she is far too modest to just ‘be bold’. So this personal
experience made me change my mind: an abundance of well organized
and formatted stubs can serve a purpose, and who knows how many
articles will be extended by other bots from other sources, and
some day nature lovers will turn to Wikipedia in much larger
numbers and manually build on the rudimentary framework. In its
earliest years Wikipedia proved an unbelievable success, it was a
miracle. A few years later when Steve Coast expressed his vision
for a free world wide street map it seemed already ‘tough but
doable’. So who can say what will happen with up to 8 million
taxonomy stubs in another decade?
The potential editor base who could add to these taxonomy
articles is huge. In a Dutch context: 1:100 Dutch (152K in 2011) is
member of a society for protection of birds, 6 other nature clubs
are even larger, up to 5-fold. The club for nature guides/educators
has 20K members. So if we can spread the word more effectively and
solicit support from a tiny fraction of those nature lovers, a fair
share of those taxonomy stubs could start to blossom in coming
years. How about a Wiki Loves Nature picture contest?




















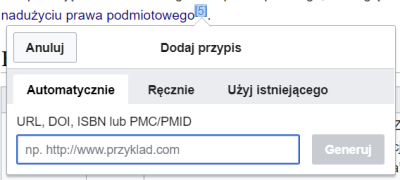



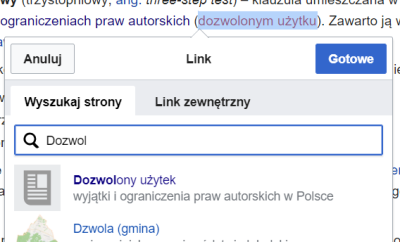
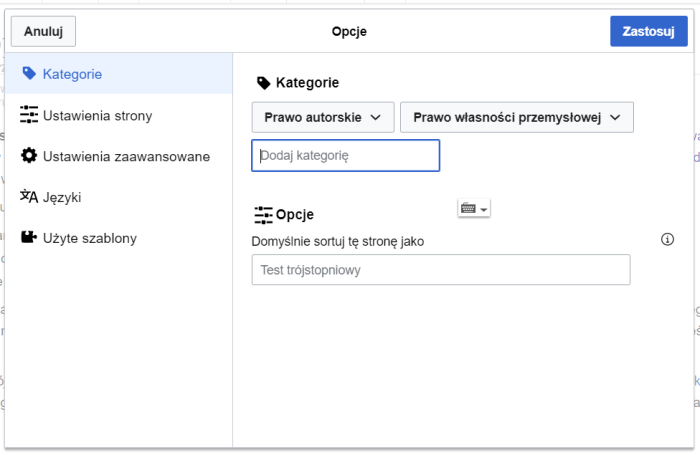



 kosztem rozwijania tej wielkiej rzeczy, którą
już mamy.
kosztem rozwijania tej wielkiej rzeczy, którą
już mamy.

_Visuals_Timeline_Working_Groups_2.png){kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}